It has been about 2 months since our latest release, and a lot has happened!
We’re happy to announce to availability of our 0.30 preview release. Please take it for a spin. If you find a bug, please create a bug ticket, if there’s functionality you’d like to see, please create a feature request.
Direct download here
Release Notes: 0.30
Over 100 tickets have been closed in this release, here we will discuss the major changes.
What is Project Hop
Project Hop’s goal is to provide an easy, flexible and metadata-driven way of data processing and data orchestration. We want you to spend as little time as possible on technical details, so you can focus on processing your data and orchestrating your pipelines.
We used the Kettle (Pentaho Data Integration) 8.2.0.7 code base to start building our architecture, but that was just the start of our journey as a separate platform.
We’ve come a long way from that starting point: a lot of the code base has been removed or changed, we’ve implemented a lot of our architecture and a lot of new functionality has been added.
Let’s have a look at what to expect in this release.
Code Cleanup, Refactoring
We have continued what we started in release 0.10 and 0.21 and are now confident to inform you all that our API should be stable. No major refactoring will be done from this point forward, small tweaks are still a possibility but our focus will now be to provide you all with a 1.0 release as soon as possible.
Hop Concepts
After some discussion we noticed that the path we took in our previous releases was the correct path, but some additional tweaking was required.
The Hop Environments have been renamed and have a new purpose! We will soon update our concepts page to reflect the new structure and deepen in how it all functions.
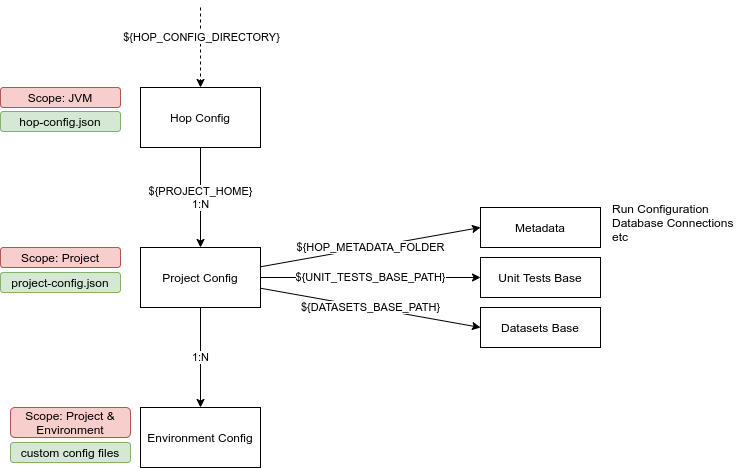
Environments → Projects, Environments and Purposes
The environments system, introduced earlier this year, was significantly extended.
-
a project is a set of workflows and pipelines with their datasets, tests etc.
-
environments contain configurations for the environments you want to run a project’s workflows and pipelines. Each environment has a purpose: Development, Testing, Acceptance, Production, Continuous Integration or Common Build
Projects and environments inherit variables and configuration from higher levels, but can can also have their own.
All functionality to list, create, edit and delete projects, environments and their purpose is available in the hop-config command line tool as well.
Plugins
We want to make Hop as robust and flexible as possible. We’ve done a lot of work to move Hop to a kernel-based architecture. To get there, we’ve moved all non-essential functionality out of the Hop engine and into plugins. Going forward, every single piece of functionality will be supported by the engine, but implemented as a plugin.
The current status of functionality that has been ported from the engine to plugins is:
-
Database plugins: all done
-
Workflow actions: all done
-
Transform actions: Around 20 remaining, but all core transforms have been done. Most of these are now being ported on request.
Apache Beam Support
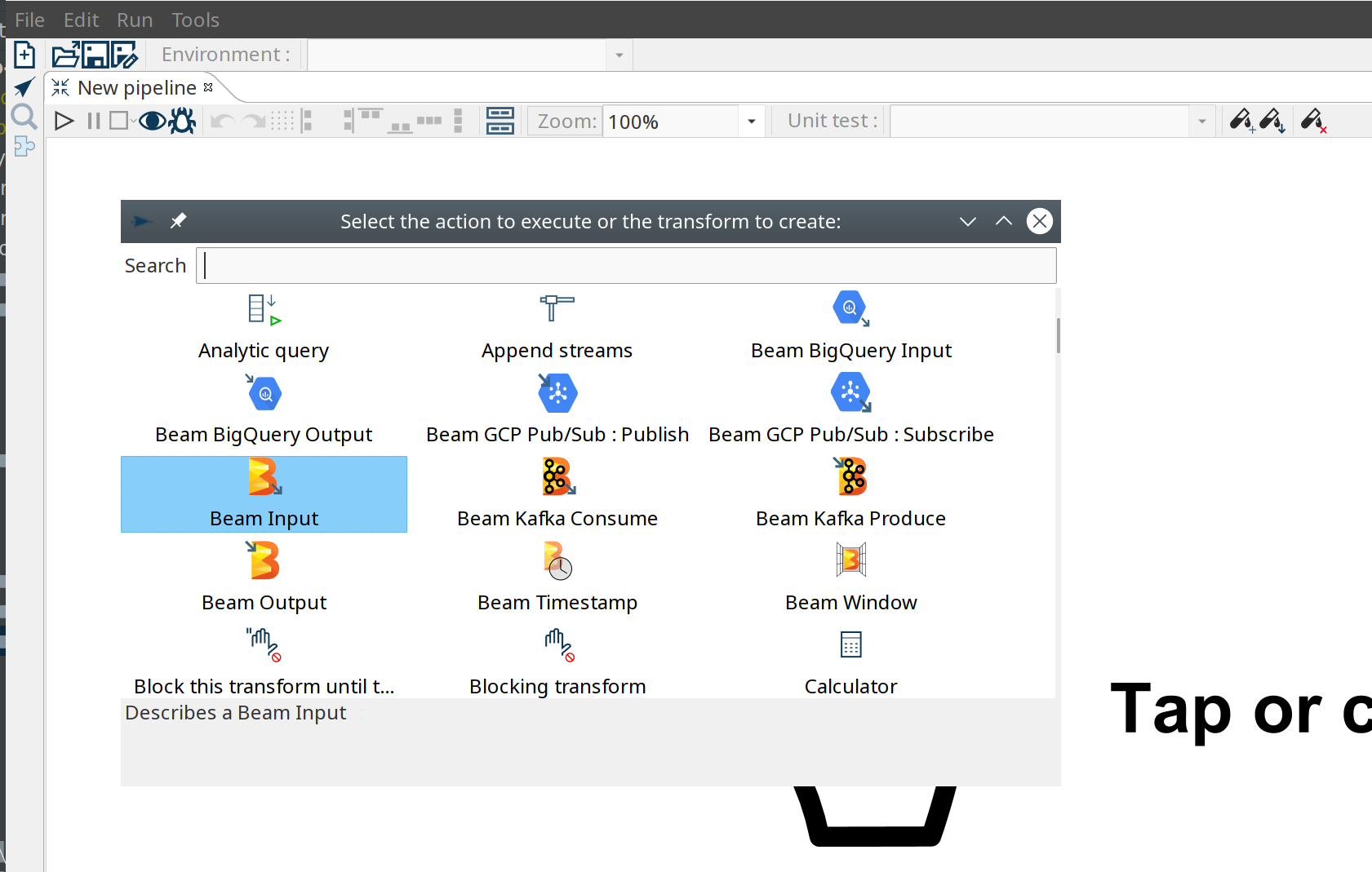
We now have integrated support for Apache Beam. Beam is an advanced unified programming model that lets you implement batch and streaming data processing jobs that run on any execution engine.
The Beam integration comes with a number of additional transforms:
-
BigQuery input and output: read from and write to Google BigQuery tables
-
GCP PubSub subscribe and publish: read from and write to Google Cloud PubSub
-
Kafka Consume/Produce: read from and write to Kafka streams
-
Beam Input/Output: define where Beam should read files from or write files to
-
Beam Timestamp: add timestamps to a bounded data source
-
Beam Window: create a Beam window
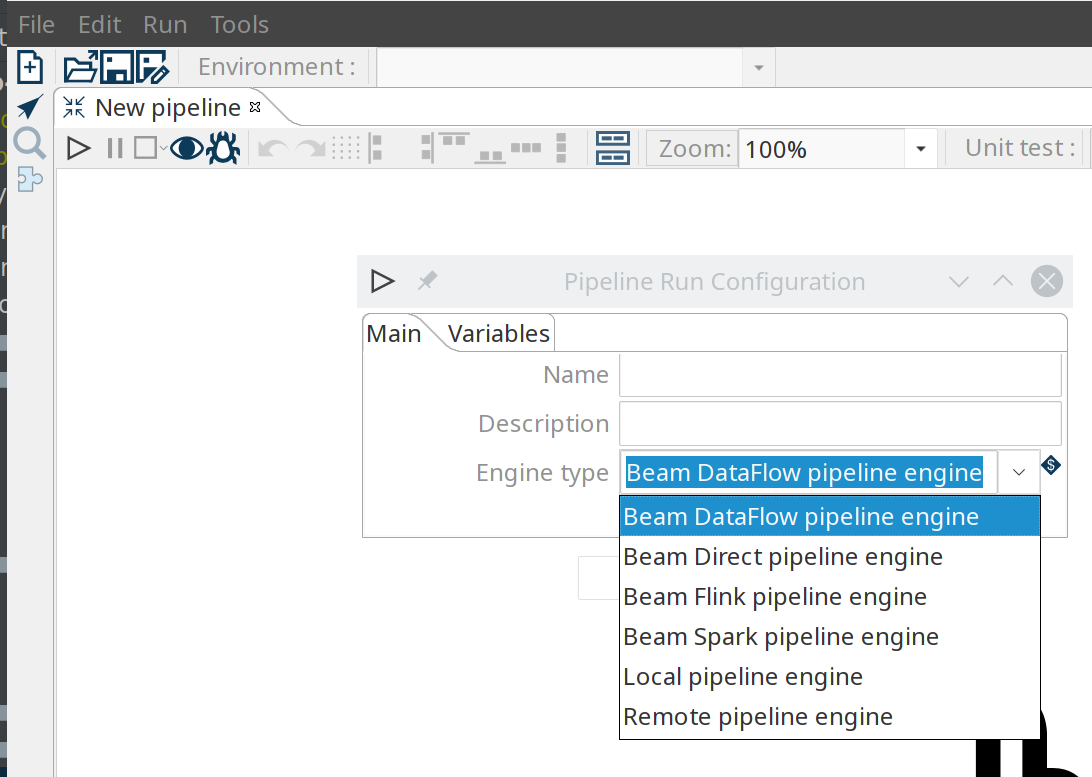
Beam adds 4 additional pipeline run configurations:
-
Beam DataFlow pipeline engine: run pipelines on Google DataFlow
-
Beam Direct pipeline engine: a local pipeline engine provided by the Apache Beam community as a way of testing pipelines
-
Beam Spark pipeline engine: run pipelines on Apache Spark
-
Beam Flink pipeline engine: run pipelines on Apache Flink
The support for these 4 additional engines brings us closer to the "design once, run anywhere" goal we share with Apache Beam. With Hop’s native local and remote pipeline run configurations, we now have 6 supported engines to run your pipelines on.
Containers
Diethard Steiner, a long time Kettle and now Hop community member and famous blogger wrotes posts about running Hop on Docker and Kubernetes.
The goal of the hop-docker project is to allow Hop to run in both short and long-lived containers.
Diethard and other community members (Hans, Rogier, Uwe) worked together and contributed their efforts to Project Hop.
Check this project out:
-
GitHub repository: https://github.com/project-hop/hop-docker
-
Docker Hub: https://hub.docker.com/r/projecthop/hop
UI
A new file dialog has been introduced replacing the default file system dialogs, this was done to optimally implement VFS support and to include a web based version of Hop (WebHop) in future releases.
We focused on implementing the core functionality first, in the next releases we will focus on User eXperience. Some of the dialogs still need a finishing touch and some cleaning up, but overall we are really pleased with the results and we hope you love the UI as much as we do.
For those that have not yet heard of Web Hop:
WebHop
WebHop is the ability to open/edit and create workflows and pipelines using your browser. The code originally started as a fork created by Hiromu, his fork now has a branch in the Hop code base and we are working on creating a single code base to distribute both version.
Metastore → Hop Metadata
While reviewing our licensing in preparation for the Apache incubation process, we found the Metastore to be LGPL-licensed.
This LGPL module created a licensing conflict (as is still the case in Kettle) with the rest of the (APL2.0 licensed) Hop code.
As we’ve gotten used to turn problems into opportunities, we decided to get rid of the Metastore entirely.
Exit Metastore, enter Hop Metadata, a much more lightweight and flexible serialization component for all Hop metadata objects. All Hop Metadata objects are now plugins, serialized in JSON.
Documentation
As stated with the previous release, our documentation is a work in progress… Now all Transforms and Actions have documentation available in the user manual. We would like to thank the community members that took the effort to check the documentation and create tickets when noticing errors or missing documentation.
Now that the bulk of the API work is finished and we are comfortable with the concepts we have introduced in the past months, we can start documenting and explaining all buttons and features in Hop.
Future
With this release we are comfortable to start the Apache Incubator process, most of the licencing issues have been resolved. The code base has had it’s first big cleanup. The new core concepts and features are in place. Our focus will now be user experience, documentation and working towards a first production ready release.
Call For Contributors
Project Hop is a team effort, we need your help to make this a success!
Contributing is much more than writing code. A couple of ways you can help out are
-
testing and creating bug tickets
-
create feature requests
-
write documentation
-
spreading the word
Check out the Contribution Guide to find out how you can contribute.
Contributions in any shape or form are greatly appreciated!