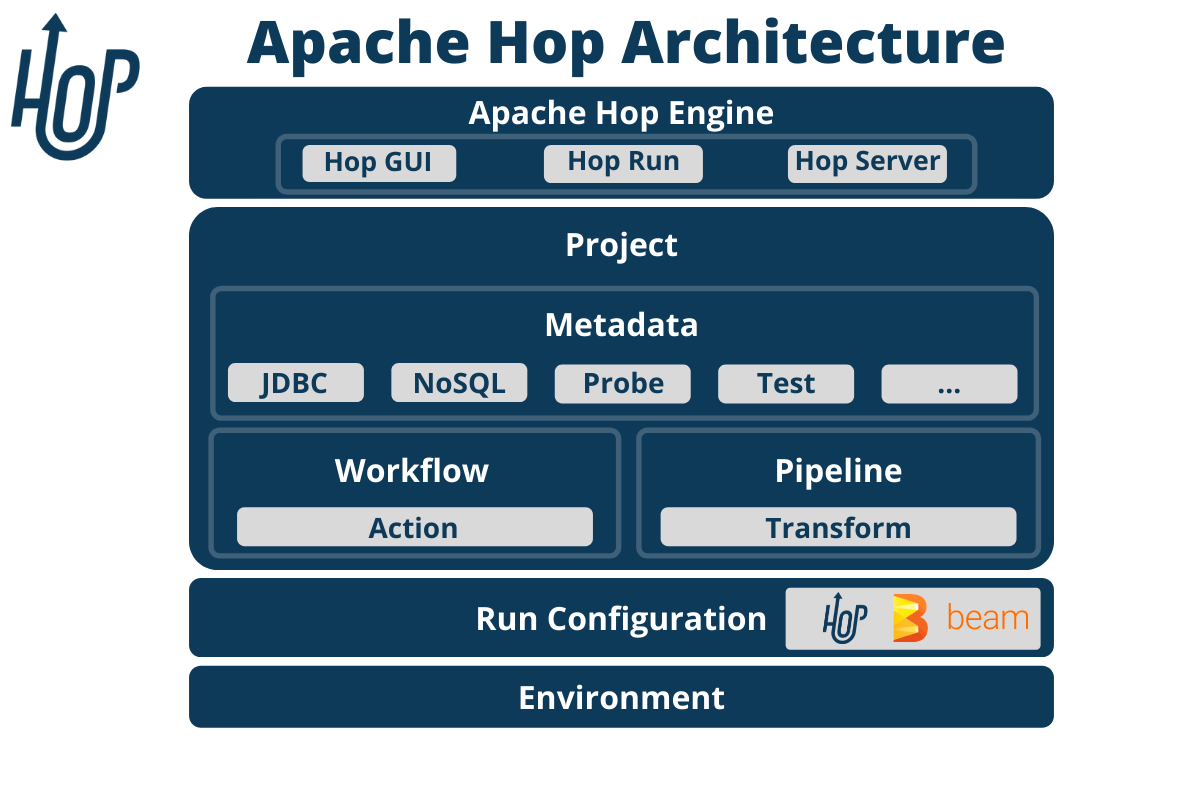
Apache Hop Architecture
The Hop architecture is very simple in essence: separate out any metadata from runtime code and tooling.
Doing this, Hop aims to have a minimal installation footprint and wants to be stateless to facilitate execution on a variety of platforms like Spark and Flink, but also in a variety of scenarios like running in different life cycles such as development, test, acceptance, production, unit testing and continuous integration.
The way these goals are achieved is by allowing orchestration workloads, defined in the broadest possible sense, to be defined as metadata. This metadata can then be expressed in various ways like an XML or JSON document, a database of any type or indeed a graphical user interface. The user interfaces delivered by this project needs to cover 100% of all functionality, removing the need for external editors or tools.
Apache Hop decided to use a single metadata interface for all expressions of metadata. Once orchestration metadata is defined we offer tools to execute as flexibly as possible: locally or remotely in the native Hop engine, on Apache Spark, Apache Flink or Google Cloud Dataflow through Apache Beam, with additional runtime engines like Apache Airflow planned for futre versions.
Workflows and pipelines
The core concepts and main file types in Hop are pipelines and workflows.
Pipelines perform the heavy data lifting: in a pipeline, you read data from one or more sources, perform a number of operations (joins, lookups, filters and lots more) and finally write the processed data to one or more target platforms.
Pipelines are networks of transforms. Each transform reads from a data source, writes to a target platform or performs an operations on the data in the pipeline. The transforms in a pipeline all run in parallel and are connected through hops that pass data between connected transforms.
Workflows take care of the orchestration work: prepare the environment, fetch remote files, perform error handling and executing child workflows and pipelines.
Workflows consist of a series of actions that are executed sequentially by default. The actions in a workflow do not operate on the data directly but return an exit code that can be used to determine the sequence of actions (through succes, failure or unconditional hops) to be followed in a workflow.
Apache Hop Engine
The Hop engine is designed to be as lightweight and as small as possible (but not smaller). The engine focuses on one thing and one thing only: execute workflows and pipelines through metadata.
All non-essential functionality is added through plugins. This includes all the actions in a workflow, all the transforms in a pipeline, all connections to relational and NoSQL databases, even the runtimes the workflows and pipelines run in.
The Hop engine is available through a number of clients that each serve their own purpose:
-
Hop GUI is the visual IDE where data teams develop, test, run and debug workflows and pipelines.
-
Hop Run is the command line interface to run workflows and pipelines on headless servers, containers, kubernetes pods and so on
-
Hop Server is a lightweight web server to run workflows and pipelines remotely through a number of REST calls
Metadata
Everything in Hop is defined as metadata: projects, environments, runtime configurations, even the workflows and pipelines themselves are defined as metadata. All metadata is stored in a project’s metadata folder, defined as JSON files, and integrates perfectly with version control systems.
Life Cycle management
Apache Hop recognizes that workflows and pipelines are the workhorses in any data engineering project, but are just one aspect in a data engineering and data orchestration project’s life cycle.
Apache Hop projects can be managed through the entire project life cycle environment through integrated version control, pipeline unit tests and integration with CI/CD platforms.
Projects and environments
Projects and environments are cornerstones in Hop projects. All the metadata, workflows and pipelines are defined in a project. Environments allow a flexible decoupling between code and configuration. Where projects specify how data needs to be processed, environments specify where that information needs to be processed.
For example, a project can contain the definition of a database connection sales or a Spark cluster. In the environment, the data team decides which database the sales data will be read from or written to or which Spark cluster the code will run on.
Each project can be linked to multiple environment for e.g. local development, lab environments, CI/CD and ultimately acceptance and production environments.
Run Configurations
A run configuration is a plugin type in Apache Hop that determines where a given project, workflow or pipeline will be executed. Run configurations are designed to leverage the capabilities of platforms like Hop itself, Apache Beam and others.
These flexible run configurations allow Hop workflows and pipelines to be designed once and run anywhere, so data teams can follow the data to be processed where it makes most sense.