In the month since we released 0.10, we’ve added enough functionality to Project Hop for another preview release.
We’re happy to announce to availability of our 0.21 preview release. Please take it for a spin. If you find a bug, please create a bug ticket, if there’s functionality you’d like to see, please create a feature request.
Direct download here
What is Project Hop
Project Hop’s goal is to provide an easy, flexible and metadata-driven way of data processing and data orchestration. We want you to spend as little time as possible on technical details, so you can focus on processing your data and orchestrating your pipelines.
We used the Kettle (Pentaho Data Integration) 8.2.0.7 code base to start building our architecture, but that was just the start of our journey as a separate platform.
We’ve come a long way from that starting point: a lot of the code base has been removed or changed, we’ve implemented a lot of our architecture and a lot of new functionality has been added.
Let’s have a look at what to expect in this release.
Code Cleanup, Refactoring
A lot of refactoring was required to bring the Hop code base up to date, more flexible and more pluggable. We’ve also massively refactored the code to reflect the Hop concepts.
After the bulk of the code cleanup and refactoring in 0.10, we’ve continued to clean up and standardize the Hop API. There have been changes in the metastore api and smaller standardizations in the overall Hop API. After 0.10, these have been evolutions rather than revolutions, and we consider the API to have become a lot more stable with this release.
Hop Concepts
Hop’s tools reflect its Architecture, check out the Concepts page.
Our main concepts are:
-
Workflows manage the orchestration of your Hop code. Workflows have actions as their main items of work.
-
Pipelines are where the real work is done. Pipelines consist of a number of transforms that each perform atomic tasks (read, transform, write) in your pipeline.
The tools we have available at the moment are:
-
hop-gui: a visual IDE to design, test and run your workflows and pipelines.
-
hop-run: a command line tool to run your workflows and pipelines
-
hop-server: a lightweight web server to run your workflows and pipelines over a REST interface
-
hop-translator: a helper tool to translate Hop into your language
-
hop-conf: environment configuration tool
Plugins
We want to make Hop as robust and flexible as possible. We’ve done a lot of work to move Hop to a kernel-based architecture. To get there, we’ve moved all non-essential functionality out of the Hop engine and into plugins. Going forward, every single piece of functionality will be supported by the engine, but implemented as a plugin.
The current status of functionality that has been ported from the engine to plugins is:
-
Database plugins: all done (39)
-
Workflow actions: all done (53)
-
Transform actions: 90+ done (less than 50 to go, NOTE: porting the transforms to plugins is more complex since some of them need significant code refactoring.
UI
There is a new context menu for hops in the Hop Gui:
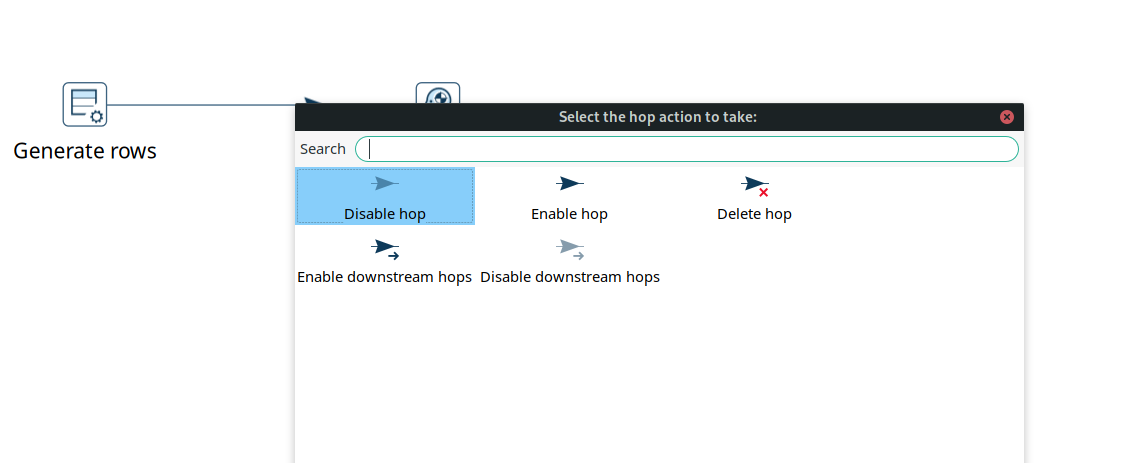
Hop Gui now has functionality for environment configuration and unit testing, see details below.
Environments
The concept of using Environments is not new, the idea has been around for a while. For those of you that work in a setting where you have multiple set-ups/environments it has always been a hassle. You had to copy around properties files and change database connections when switching between systems or teams. The environments solve this! It allows you to create multiple set-ups and you can switch between them without restarting the GUI. It even remembers which tabs you were working on previously and re-opens them for you.
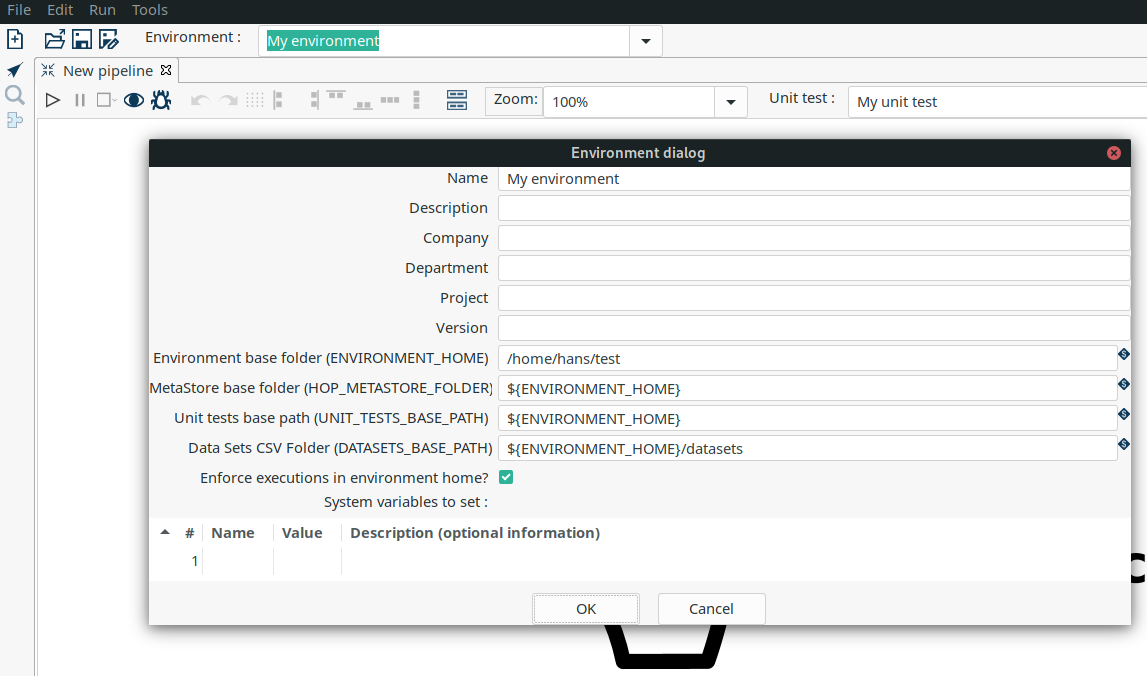
To see the Environments in action you can watch following short video:
With the environment configuration comes a new tool hop-config, that brings the entire Hop configuration management much more up to date.
Unit testing
Unit testing is a process where you check if your code, or in this case your data pipelines, respond the way you intended them to do. This is done by adding a sample dataset to a pipeline and then validating the result against another dataset. When the result matches your "Golden Data" the test passes, when it doesn’t you raise an error. This is a great way to see if all your special use cases are covered by the pipeline. It can also be used to make upgrading to a new version of the software hassle free.
We added this testing framework because we believe your data pipelines should be managed like regular software projects, and these require testing and validation. We will also be using this to add another layer to our own code quality. Not all checks and tests can be done using regular Unit tests so we are planning to check every transform with a unit test. Spotting regressions and before they reach the final product.
Following video shows unit testing in action:
Documentation
The last couple of weeks we have been hearing the same question multiple times. And we feel the same! Currently our Documentation is, how should we put it… A bit lacking… We have been focusing mainly on code to get you this 0.10 and now 0.21 release.
We do have a great getting started but our user manual is currently falling a bit short. After the 0.21 release we will focus on catching up on documentation.
The documentation now has a search option to quickly find the information you need.
We’re looking for people who want to help us write or translate documentation. Contact us and we’ll be happy to get you started.
Future
Work isn’t done with this new preview release.
Next up are more runtime engine implementations. The first engine we’ll support will be Apache Beam, but there will be many more.
We intend to start the Apache Incubation process soon. We strongly believe the move to Apache Hop will increase Project Hop’s adoption. We are looking forward to working with the Apache Software Foundation and to integrating with the great software they provide.
Call For Contributors
Project Hop is a team effort, we need your help to make this a success!
Contributing is much more than writing code. A couple of ways you can help out are
-
testing and creating bug tickets
-
create feature requests
-
write documentation
-
spreading the word
Check out the Contribution Guide to find out how you can contribute.
Contributions in any shape or form are greatly appreciated!