Concepts
Tools
- Hop Conf
Hop Conf is a command line tool to manage various aspects of your Hop configuration: projects, environments, cloud configuration and more
- Hop Encrypt
Hop Encrypt is a command line tool that obfuscates or encrypts a plain text password for use in XML, password or metadata files. Make sure to also copy the password encryption prefix to indicate the obfuscated nature of the password. Hop will then be able to make the distinction between regular plain text passwords and obfuscated ones.
- Hop Gui
Hop Gui is the visual IDE where Hop data developers create, test, run and manage the life cycle for workflows and pipelines. In addition to functionality for development and life cycle management, Hop Gui contains tools and perspectives to manage projects and environments, to search and manage metadata, to manage and version control a large variety of files and to explore logging in a Neo4j graph.
- Hop Run
Hop Run is a command line tool to run workflows and pipelines, with options to (list or) specify projects, environments, properties and run configurations.
- Hop Search
Hop Search is a command line tool to search all metadata available in a specific project or environment.
- Hop Server
Hop Server is a web service interface to manage and run workflows and pipelines.
Item types
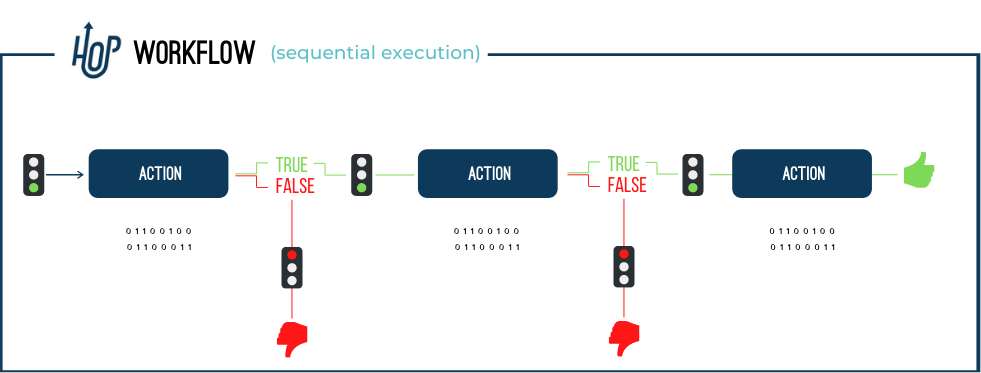
- Action
An Action is one operation performed in a Workflow. Actions are executed sequentially by default, with parallel execution as a configuration option. An Action returns a true or false exit code, which can be used (or ignored) in the Workflow’s execution.
- Hop
A Hop links Actions in a Workflow or Transforms in a Pipeline. In Workflows, Hops operate based on the exit status of previous Actions, Hops in Pipelines pass data between Transforms.
- Pipeline
Pipelines are the actual data workers. Operations in a Pipeline read, modify, enrich, clean and write data. Orchestration of Pipelines is done through othere Pipelines and/or Workflows.
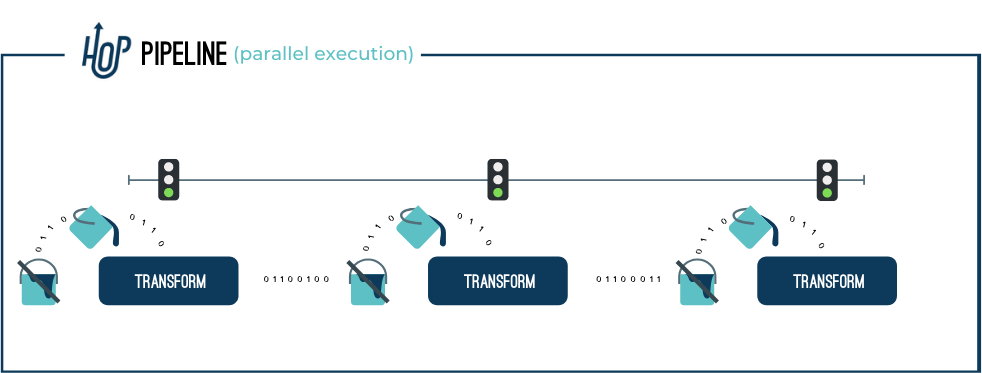
- Transform
A Transform is a unit of work performed in a Pipeline. Typical Transform operations are reading data from files, databases, performing lookups or joins, enriching, cleaning data and more. All transforms in a Pipeline are executed in parallel. Transforms process data and move batches of processed data on Hops for processing by subsequent Actions.
- Workflow
A Workflow is a sequence of operations that are performed sequentially by default (with optional parallel execution). Workflows usually do not operate on the data directly, but perform orchestration tasks. Typical tasks in a Workflow consist of retrieving and archiving data, sending emails, error handling etc. )
Projects and Environments
- Project
Hop Projects are a conceptual grouping of configurations, variables, metadata objects and workflows and pipelines. Projects can inherit metadata from parent projects. A project contains one or more environments where the actual configuration is defined.
Example: a 'Sales' project contains a 'customers' database connection and a number of workflows and pipelines. The runtime configurations, database connection properties etc are defined in the 'dev', 'uat' and 'prd' environments.
- Environment
Hop Environments are instances of projects that hold the actual runtime configurations and other metadata objects for a project.
Example: the 'dev' environment for the 'Sales' project specifies to read from host '10.0.0.1' for the 'customers' database connection
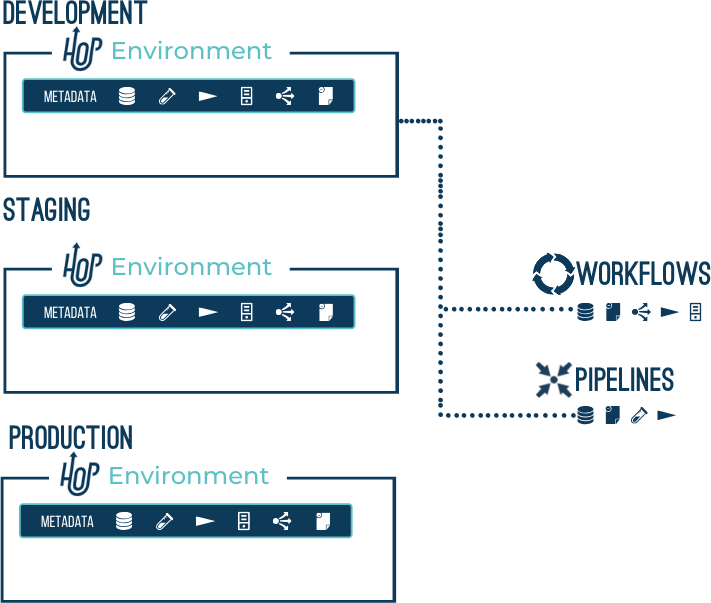
Metadata
Hop Metadata is the central storage repository for shared metadata like relational database connections, run configurations, servers, git repositories and so on. Metadata is persisted as json and is stored by default in a project’s base folder.
Data types
As a best practice for producing consistent, predictable outcomes when working with your data in Apache Hop, you must consider how the Apache Hop engine processes different data types and field metadata in transformations and jobs.
| As a rule, data is never modified by metadata inside of Apache Hop. Data is only modified when Apache Hop writes to files or similar objects, but not to databases. |
Apache Hop data types map internally to Java data types, so the Java behavior of these data types applies to the associated fields, parameters, and variables used in your workflows and pipelines. The following table describes these mappings.
| Apache Hop | Java data type | Description |
|---|---|---|
BigNumber | BigDecimal | An arbitrary unlimited precision number. |
Binary | Byte[] | An array of bytes that contain any type of binary data. |
Boolean | Boolean | A boolean value true or false. |
Date | Date | A date-time value with millisecond precision. |
Integer | Long | A signed long 64-bit integer. |
Internet | Address | InetAddress An Internet Protocol (IP) address. |
Number | Double | A double precision floating point value. |
String | String | A variable unlimited length text encoded in UTF-8 (Unicode). |
Timestamp | Timestamp | Allows the specification of fractional seconds to a precision of nanoseconds. |
| Apache Hop also comes with a number of additional complex data types (e.g. Avro, JSON, Graph) that have no one-on-one mapping to Java data types. These data types only work with specific transforms and can’t be used in general-purpose transforms. |
Conversions and comparisons
Nulls and sort order
-
Null handling and sort behavior follow Java comparison semantics for the mapped type, unless noted below.
String parsing/formatting
-
When converting from a String to another type, Hop uses the format settings defined in the transform metadata (for example, date masks, decimal symbols, and grouping characters).
-
When converting from another type to a String, Hop applies the same metadata-based format.
For these reasons, it is important to be explicit about formats when working with String types. A common issue arises with decimal separators, which may differ between environments. For example, an EU locale typically uses , for decimals, while a US locale uses .. Using an explicit format avoids these inconsistencies.
Timestamp
A Timestamp value can be created from a Date, String, Number, or another Timestamp.
Conversions
-
Date → Timestamp: Represents the same instant; fractional seconds default to
0. -
String → Timestamp: Parsed using the specified date mask (for example,
yyyy-MM-dd HH:mm:ss). -
Number → Timestamp: Interpreted as nanoseconds since the epoch.
UUID
UUID values map to java UUID object that stores them as 16-byte type. Storing a UUID with the String type uses 32-byte. The difference in storage is noticeable in many situations like inserting in a database with native UUID support.
When using MongoDB, Hop writes UUIDs using the STANDARD representation, which corresponds to BSON Binary subtype 4.
Sorting
Databases may order UUID columns by their raw binary value (as is the case in PostgreSQL). Hop, however, compares UUIDs by their two 64-bit halves as signed longs — first the most significant bits (MSB), then the least significant bits (LSB). These ordering methods can differ. To ensure consistent results, perform all sorting either within Hop or entirely in the database.
Gotchas
Writing a UUID to a database without native support as a UUID type (e.g. MySQL) will fail. Convert them to String before writing.
JSON
The JSON type in Hop follows the official JSON standard: https://www.json.org/json-en.html. It is treated as an unordered set of key/value pairs. This means that JSON values may behave differently from their String representations. For example, consider these two JSON objects:
{ "a": 1, "b": 2 }{ "b": 2, "a": 1 }When treated as String, they are different. When treated as JSON, they are considered equal. Because JSON comparison in Hop performs structural checks, it is generally more robust — but also slightly slower — than string comparison.
Sorting
The way Hop sorts JSON values resembles how PostgreSQL sorts JSONB values. Keys are sorted alphabetically, and values are compared in the following type order:
NULL < MISSING < BINARY < STRING < NUMBER < BOOLEAN < ARRAY < OBJECTArrays are compared element by element; if all compared elements are equal, the longer array is considered greater.
MongoDB
The JSON type supports all standard JSON values when reading or writing to MongoDB. Values that are part of MongoDB’s extended JSON (for example, Date objects) are not supported. To fully support MongoDB-specific BSON values, use the String type instead.
Various
The following items are an alphabetically ordered list of concepts that are used throughout Hop and will be mentioned at various locations in the Hop tools and documentation.
- Lazy Loading
If enabled, all data conversions (character decoding, data conversion, trimming, …) for the data being read will be postponed as long as possible, effectively reading the data as binary fields. Enabling lazy conversion can significantly decrease the CPU cost of reading data.
When to avoid: if the data conversion needs to be performed later in the stream anyway, postponing the conversion may slow things down instead of speeding up.
When to use: use cases where Lazy Conversion may speed things up when 1) data is read and written to another file without conversion, 2) data needs to be sorted and doesn’t fit in memory. In this case, serialization to disk is faster with lazy conversion because encoding and type conversions are postponed, or 3) bulk-loading to database without the need for data conversion. Bulk loading utilities typically read text directly and the generation of this text is faster (this does not apply to Table Output).