After more than two years of work, the Apache Hop community is pleased to announce the general availability of Apache Hop (Incubating) 1.0.

This 1.0 release is the result of a massive amount of work by the Apache Hop community.
Code Architecture, cleanup, refactoring
Since Apache Hop started from the Kettle (Pentaho Data Integration) code base in late 2019, no stone has been left unturned. All dependencies have been brought up to date, huge parts of the existing code base were removed or rewritten, literally not a single file has been left untouched.
The result of all this cleaning and refactoring is a clean and well-architected Hop engine. All non-essential functionality was trimmed out and moved to plugins. Hop now supports over twenty plugin types, for a total of over 400 plugins.
With this revamped architecture, Hop is capable of processing data on IoT edge devices to petabytes of data in streaming, batch or hybrid scenarios.
Hop GUI and a uniform set of tools
Hop Gui is the visual development environment (IDE) where data developers create workflows and pipelines. Hop Gui was written from scratch and is available on all major desktop platforms: Windows, Mac OS and Linux. Hop Web provides the full Hop Gui in the browser.
The ability to visually design, run, preview, debug and maintain data workflows and pipelines allows Hop data developers to be more productive than they could ever be through "pure" code.
Hundreds of transforms and actions allow Hop data developers to build complex solutions to read, process and write data from and to a very wide variety of platforms. This includes but is not limited to relational and NoSQL databases, streaming platforms, cloud services and lots more.
There are no hidden configuration files, all of Hop’s functionality is available through Hop Gui. Alternatively, all operations to run, configure, search etc are available through a set of easy to use command line tools.
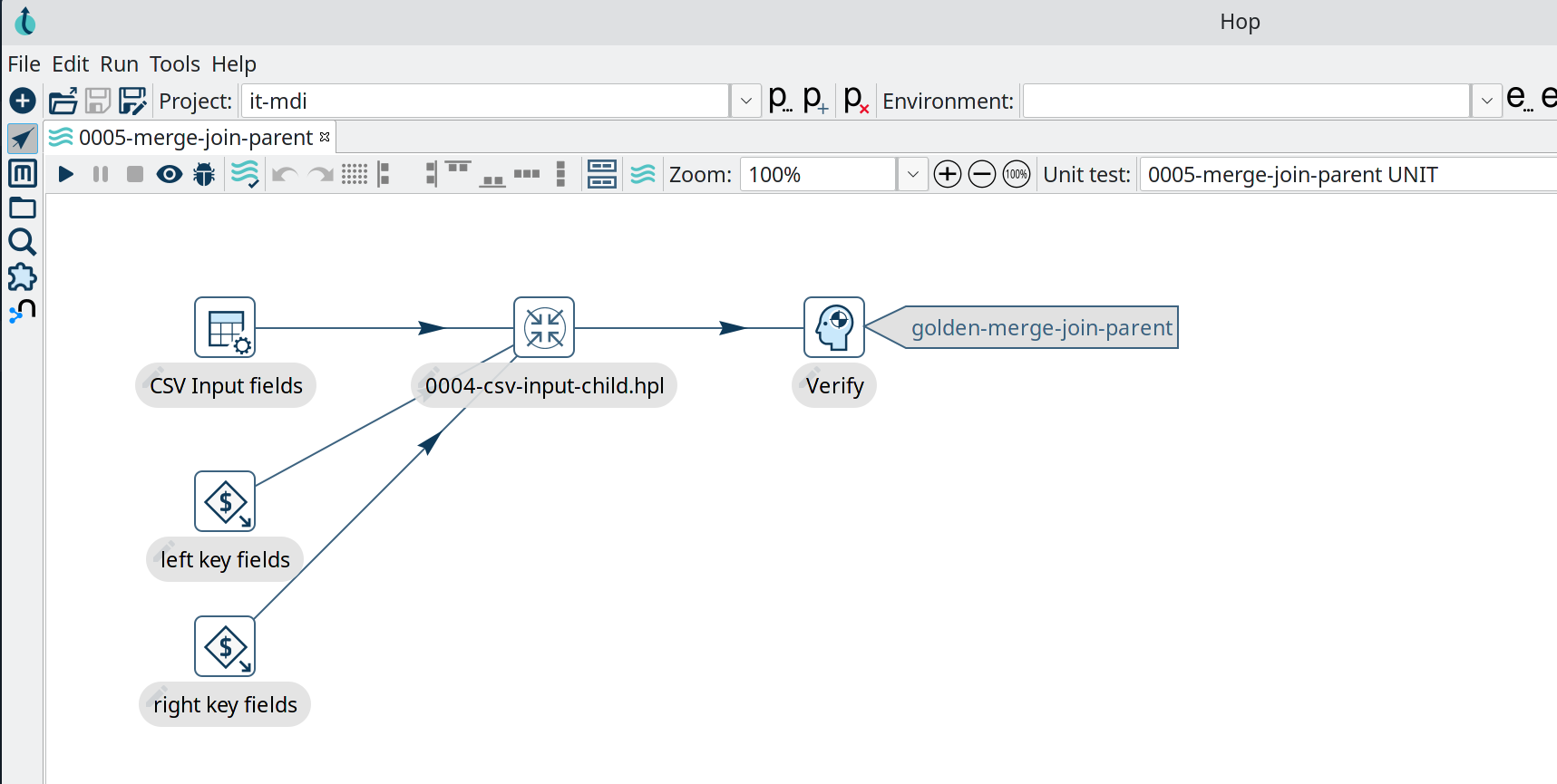
Projects and Environments
Data developers almost always work on multiple projects simultaneously and run these projects in multiple environments.
Hop projects can easily be managed from the Hop Gui and the hop-conf command line tool. For each project a number of environments can be defined, each with a specific purpose (e.g. development, testing, CI/CD). Each environment can contain a number of configuration files.
Switching between projects and environments is quick and easy from the dropdown in Hop Gui. In headless server environment, the Hop command line tools provide options to create, manage or specify projects and environments.
This strict separation between code (a project’s metadata) and configuration (environment files) lets Hop blend in seamlessly with version control and deployment systems. Hop’s file explorer perspective even allows Hop developers to manage workflows, pipelines and other metadata files in git directly, with options for common operations like pull, push, commit, there’s even a visual diff between versions.
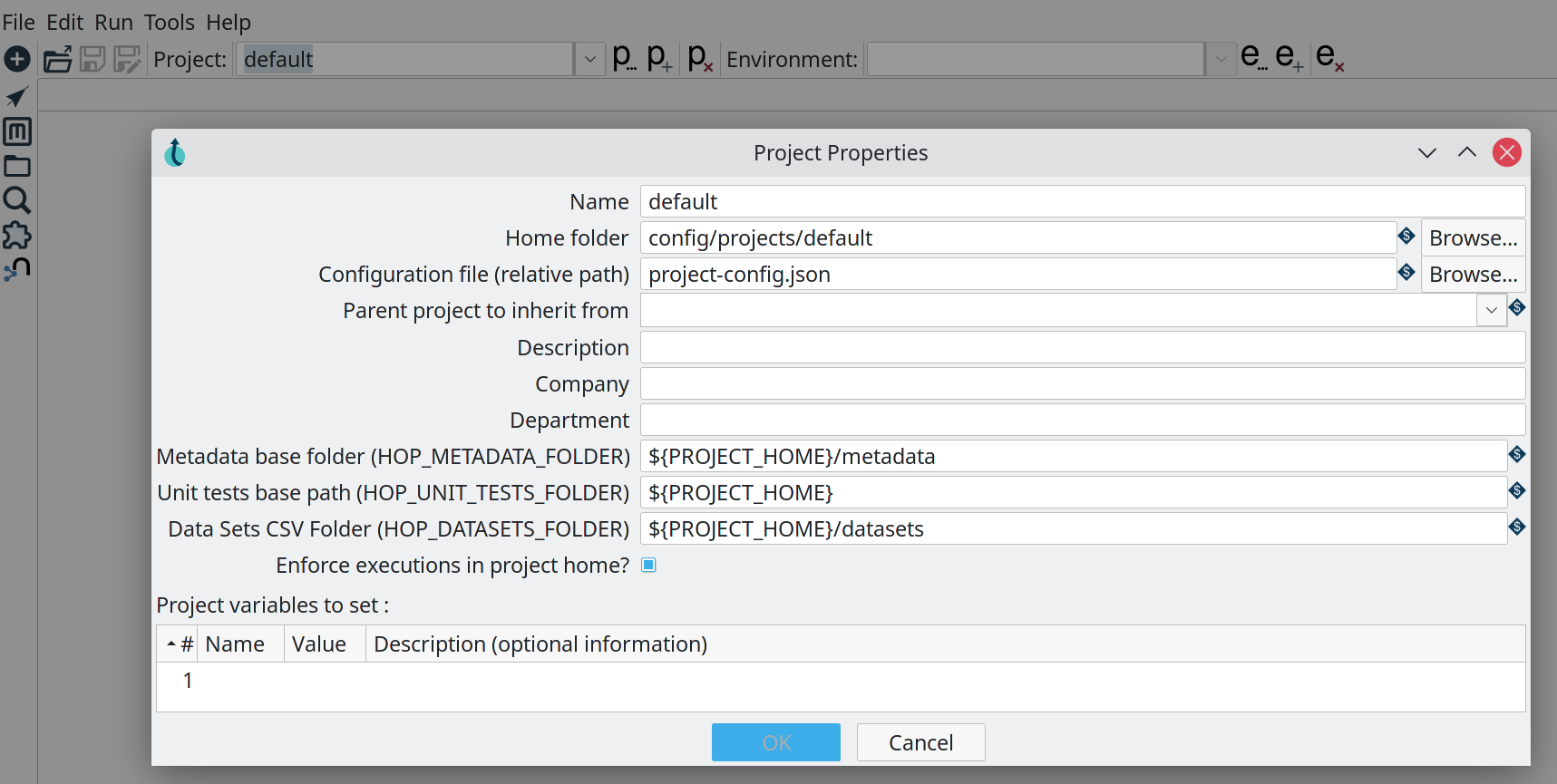
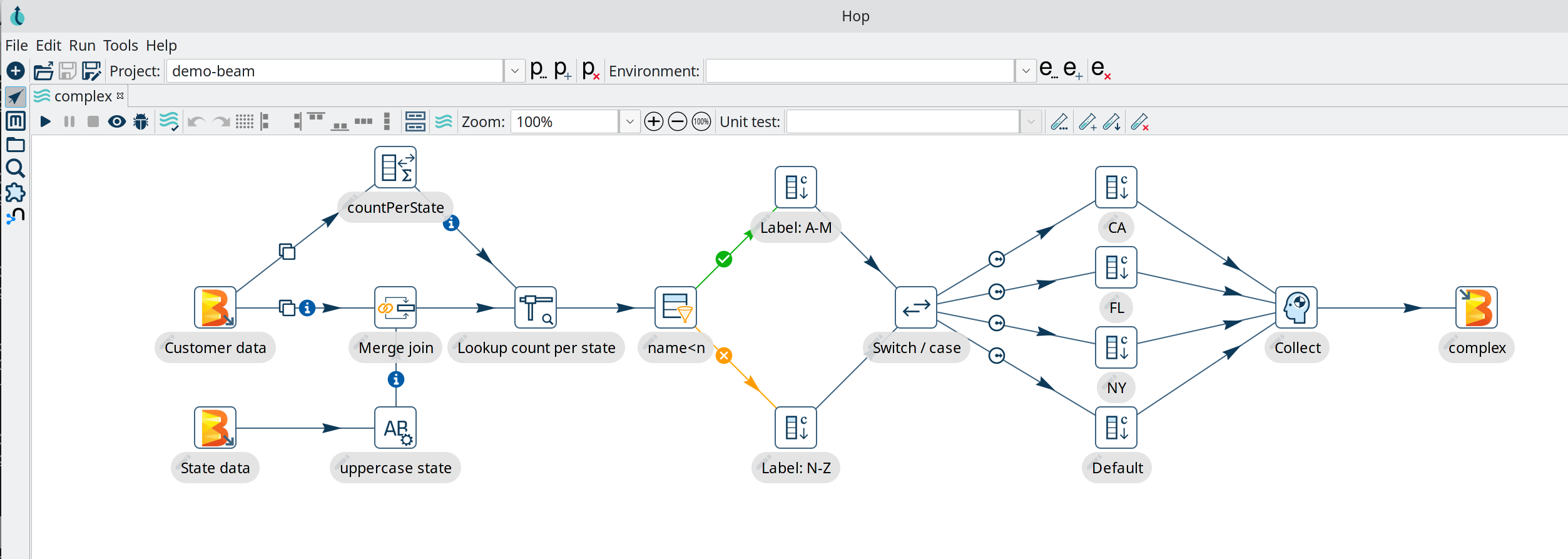
Portable runtimes: design once, run anywhere
The runtime configuration for workflows and pipelines in Hop are designed to be as flexible as possible. A workflow or pipeline is designed in Hop Gui, but can be executed on the runtime where it fits best.
In Hop 1.0 workflows have runtime configuration for the local and remote native Hop engine. In addition to the local and remote native engine, pipelines can also run on Apache Spark, Apache Flink and Google Dataflow over Apache Beam.
With portable runtimes, Hop data developers and data engineers design a workflow or pipeline in Hop Gui and deploy it to and run it in the environment where it makes most sense. This gives Hop projects the flexibility to follow your data to the environment where it makes most sense.
Unit, Integration and Regression Testing
Hop provides everything you need to handle errors in workflows and pipelines gracefully. However, knowing your projects run without errors is no guarantee that your data was processed exactly the way you want and expect it to.
Hop data developers can not only design workflows and pipelines in Hop Gui, they can also add unit tests to check if a workflow or pipeline processed the data exactly as expected. Unit tests run a pipeline for a defined input data set and compare the result that was produced to an expected (golden) data set. If the generated result matches the golden data set, the test succeeds. If it doesn’t, the test fails.
Unit tests can be combined with higher-level integration and regression tests to make sure an entire project or system behaves as expected.
A library of tests significantly improves the quality of a project. As a matter of fact, the Hop project team eats its own dog food: through a growing library of unit, regression and integration tests, the Hop developers have been able to identify and fix a number of issues that have been in the code base for over a decade.

Life cycle management
Portable runtimes, projects and environments, integrated version control, unit testing and lots of other functionality that come with Hop 1.0 provide all the tools a data team needs to manage their projects throughout the entire life cycle.
Not only do these tools allow your project to be developed, managed, tested and deployed according to general software development best practices, they also allow data projects and teams to follow their data to the platforms where it fits best.
Requirements change, just like data volumes and architectures do. Having a platform that allows you and your project to evolve with this changing landscape is crucial in a modern data-driven organization. Hop 1.0 offers everything you need to do just that.
Community
One of the core pillars of becoming an (Incubating) Apache Software Foundation project is community building.
While the Hop team has been working tirelessly on building the absolute best data orchestration and data integration platform out there, community building has been equally important. Building the best platform in the world is useless without people using it and being excited about the things they can do with that platform.
Hop has seen a tremendous growth in community adoption since the project joined the Apache Software Foundation’s incubator in September 2020. Hop now has hundreds of followers on the various social media accounts, well over 200 people are registered on the Hop chat. Local user groups have started in Brazil, Japan, Spain, Italy and more.
Even more important than the software, community is what Hop is all about. A very warm thank you and shoutout to everyone who has been involved with Apache Hop (Incubating) over the last two years. Hop 1.0 wouldn’t be the big release it is without each and every one of you!