After four and a half months of work, the Apache Hop community is pleased to announce the general availability of Apache Hop 2.1.0.
A huge thank you to everyone who made this possible.

or download Hop 2.1.0 right away.
MongoDB
![]() Apache Hop has had support for MongoDB since the very first releases, with a MongoDB connection metadata type and MongoDB input and MongoDB Output transforms. Hop 2.1.0 now adds a new MongoDB Delete transform to the mix.
Apache Hop has had support for MongoDB since the very first releases, with a MongoDB connection metadata type and MongoDB input and MongoDB Output transforms. Hop 2.1.0 now adds a new MongoDB Delete transform to the mix.
In addition to this new MongoDB delete transform, the MongoDB drivers and documentation have been updated.
-
HOP-3925 MongoDB Delete transform
Apache Beam
![]() Apache Beam has been updated to 2.41.0, with Apache Spark 3.3.0 and Apache Flink 1.15.2.
Apache Beam has been updated to 2.41.0, with Apache Spark 3.3.0 and Apache Flink 1.15.2.
The Apache Spark run configuration now supports local execution again, making it easier to test your Apache Hop pipelines on Apache Spark.
Your Apache Hop pipelines on any of the supported Apache Beam run configurations should see major performance improvements. We’ve optimized the Beam rows serialization, especially for locking, serialization and removal of redundant checks.
AWS Kinesis is now supported in the Beam run configurations with two new transforms: Beam Kinesis Consume and Beam Kinesis Produce.
Execution Information Framework and Data Profiling
A lot of the work in the 2.1.0 release was spent on a new Execution Information and Data Profiling framework.
Apache Hop users already had the flexibility to run workflows and pipelines from Hop Gui, hop-run or hop-server. What was missing was a unified, transparent and centralized way of keeping track of current and previous executions. That has now been resolved with the new execution information framework.
You can now configure your workflow and pipeline run configuration to use an execution information location. These locations can be a local file system, a remote Hop Server or a Neo4j graph database. Execution information includes the run information (parameters, variables, start and time, status and so on), the complete workflow or pipeline log, metrics and (for pipelines) optional execution data profiles.
Execution data profiles are another addition in 2.1.0 that allow pipelines to log a number of data profiles for the transforms in your pipeline. Data profiles include the minimum and maximum values, number of (non) null values and so on. Additionally, you can sample the first, last or a random set of rows.
The execution and data profiling information can be consulted in the new Execution Information perspective. This perspective not only lets you consult your execution information, but also lets you drill up to or down from the parent or child workflow or pipeline. Additionally, the embedded workflow and pipeline viewer in the perspective also lets you jump straight to the workflow or pipeline editor.
Check the Execution Information Perspective, Execution Information Location and Execution Data Profile docs for more information.
Kubernetes
![]() Apache Hop already contained a basic Kubernetes Helm chart. With Apache Hop 2.1.0, we’re also releasing new Helm charts for Hop Server and Hop Web. These do not necessarily have to follow the same release cycle as the official Apache Hop releases, hence the 0.1 version number…
Apache Hop already contained a basic Kubernetes Helm chart. With Apache Hop 2.1.0, we’re also releasing new Helm charts for Hop Server and Hop Web. These do not necessarily have to follow the same release cycle as the official Apache Hop releases, hence the 0.1 version number…
In addition to the Helm charts, the Hop docs now contain a how-to guide on running a Hop pipeline using the Flink Kubernetes operator.
Documentation
Documentation is never-ending ongoing effort. As with every release, the Apache Hop team worked hard to improve and extend the available documentation to support the Apache Hop community as good as possible.
The transform documentation pages have been updated to contain an indication of the supported engines. A lot of these are placeholders for now, but will be updated continuously.
New how-to guides were added on how to work with Joins and Lookups and on how to run workflows and pipelines from Apache Airflow with the docker operator.
The installation and configuration instructions have been extended with an upgrade section. Installing and configuring Apache Hop already always was a breeze, but this section explains a couple of tweaks.
New plugins
As with every release, a number of new plugins make their first appearance in Apache Hop:
-
transforms
-
the Microsoft Access Output transform lets you write data to Microsoft Access databases. Even though MS Access is not the most advanced data platform, it’s still an indispensable data format in a lot of organizations.

-
the Snowflake Bulk Loader transform lets you bulk upload data to your Snowflake analytical cloud databases.

-
-
databases: Apache Hive is now a fully supported database type. Support for Apache Hive was lacking in previous Apache Hop releases. That functionality gap has now been closed.

-
HOP-4003: add Snowflake Bulk Loader
-
HOP-4109: Microsoft Access connector
-
HOP-4262: Add support for Apache Hive databases
Community
The Hop community continues to grow!
The Apache Hop PMC and community welcomed one new committer since the 2.0.0 release. Shl Xue made various contributions to Apache Hop internationalization, the Chinese translation and many other areas. Thank you very much and a warm welcome, Shl Xue!
We’d also like to give a shoutout to Iranian community member @morti, who helped to identify, troubleshoot and test the Apache Beam performance improvements. Thank you, Nouri!
The overview below shows the community growth compared to the 2.0.0 release in June:
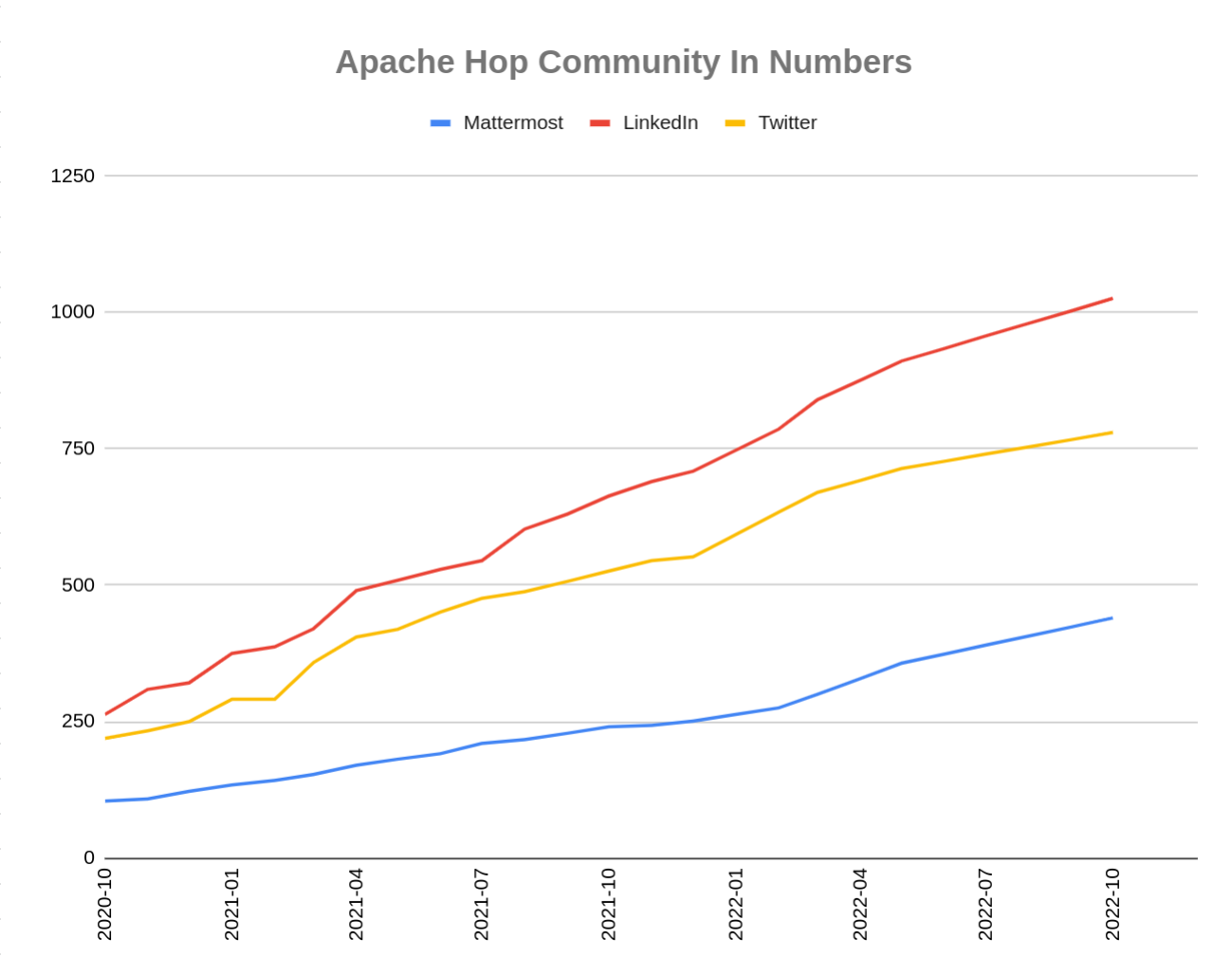
Without community interaction and contribution, Hop is just a coding club! Please feel free to join, participate in the discussion, test, file bug tickets on the software or documentation, … Contributing is a lot more than writing code.
Check out our contribution guides and Code of Conduct to find out more.
JIRA
Hop 2.1.0 contains work on 213 tickets:
-
Resolved: 204
-
Closed: 9
Check the Hop Jira for a full overview of all tickets.