Loops in Apache Hop
In any data engineering project, there are lots of use cases where you’ll want the same process to run multiple times, e.g. to loop over a number of folders, run for every available month in a data range etc.
Apache Hop offers multiple ways to loop over the same workflow or pipeline. Let’s take a closer look at the different options.
DEPRECATED: copy rows to result + execute for each row
As stated in the section title, this option is deprecated and is only available in Apache Hop for historical reasons. DO NOT use this option in new development. It does work, but it’s a lot harder to figure out what is going on inside your pipelines or workflows. If you have this type of loops in your project e.g. as part of an imported Pentaho Data Integration (Kettle) project, have a look at the other ways to build loops in this guide to refactor those loops.
In this scenario, you’ll need at least three Apache Hop files:
-
in a first pipeline, we’ll build a list of values to loop over. These rows are placed in memory with a Copy rows to result transform.
-
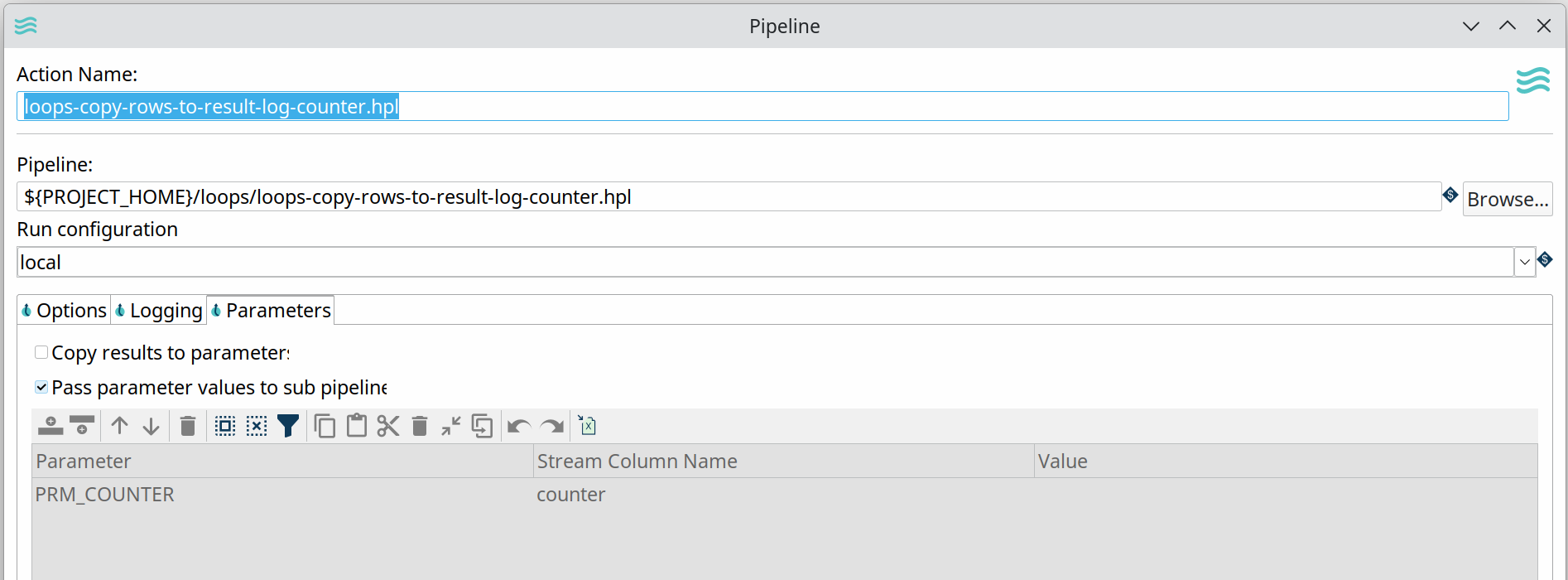
in a second pipeline, we’ll consume each of the values in the loop. Each value in the loop is accepted as a parameter in this pipeline.
-
both pipelines are executed by a workflow. The first pipeline action puts the values to loop over in memory. In the second pipeline action, we’ll enable the
Execute for every result rowoption and pass the fieldname(s) we copied to memory as aStream column nameas a parameter to the pipeline that processes the loop values.
This is what that looks like in a very basic example:

Create 10 rows with a counter to loop over. Copy these rows to memory.
Process each of the values in the loop individually. This example receives the loop value as a $${PRM_COUNTER$} parameter and prints it to the logs.
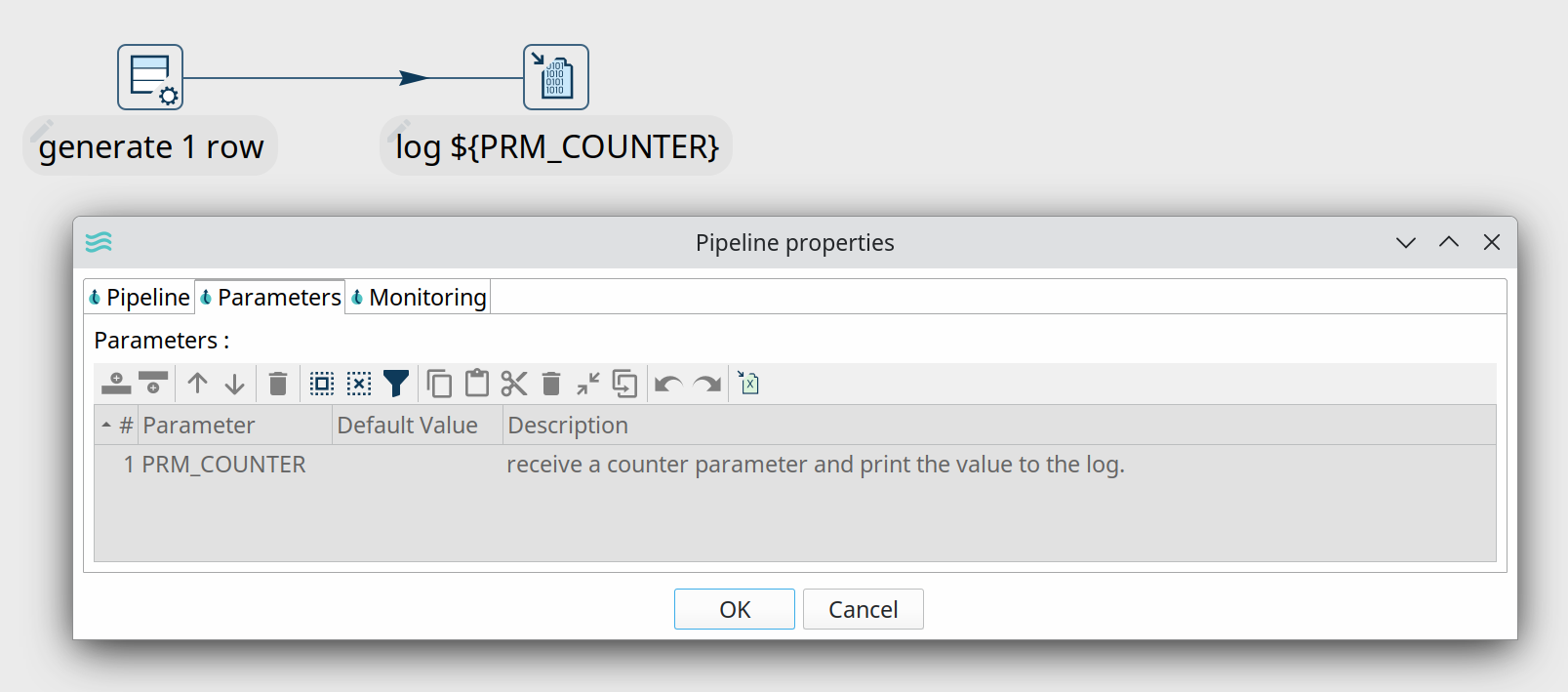
Both pipelines are executed from a workflow.

The second pipeline action in this workflow runs the pipeline where we process the loop values. The Execute for every result row option runs this pipeline for every counter value we placed in memory in the first pipeline.
The logs for this workflow will look similar to the output below:
2023/04/24 11:25:07 - Hop - Starting workflow
2023/04/24 11:25:07 - loops-process-rows-from-memory - Start of workflow execution
2023/04/24 11:25:07 - loops-process-rows-from-memory - Starting action [loops-copy-rows-to-result.hpl]
2023/04/24 11:25:07 - loops-copy-rows-to-result.hpl - Using run configuration [local]
2023/04/24 11:25:07 - loops-copy-rows-to-result - Executing this pipeline using the Local Pipeline Engine with run configuration 'local'
2023/04/24 11:25:07 - loops-copy-rows-to-result - Execution started for pipeline [loops-copy-rows-to-result]
2023/04/24 11:25:07 - generate 10 rows.0 - Finished processing (I=0, O=0, R=0, W=10, U=0, E=0)
2023/04/24 11:25:07 - add counter.0 - Finished processing (I=0, O=0, R=10, W=10, U=0, E=0)
2023/04/24 11:25:07 - Copy rows to result.0 - Finished processing (I=0, O=0, R=10, W=10, U=0, E=0)
2023/04/24 11:25:07 - loops-copy-rows-to-result - Pipeline duration : 0.052 seconds [ 0.052" ]
2023/04/24 11:25:07 - loops-process-rows-from-memory - Starting action [loops-copy-rows-to-result-log-counter.hpl]
...
...
2023/04/24 11:25:07 - loops-copy-rows-to-result-log-counter - Executing this pipeline using the Local Pipeline Engine with run configuration 'local'
2023/04/24 11:25:07 - loops-copy-rows-to-result-log-counter - Execution started for pipeline [loops-copy-rows-to-result-log-counter]
2023/04/24 11:25:08 - generate 1 row.0 - Finished processing (I=0, O=0, R=0, W=1, U=0, E=0)
2023/04/24 11:25:08 - log ${PRM_COUNTER}.0 -
2023/04/24 11:25:08 - log ${PRM_COUNTER}.0 - ------------> Linenr 1------------------------------
2023/04/24 11:25:08 - log ${PRM_COUNTER}.0 - #################################
2023/04/24 11:25:08 - log ${PRM_COUNTER}.0 - the vaule for PRM_COUNTER is now 10
2023/04/24 11:25:08 - log ${PRM_COUNTER}.0 - #################################
2023/04/24 11:25:08 - log ${PRM_COUNTER}.0 -
2023/04/24 11:25:08 - log ${PRM_COUNTER}.0 -
2023/04/24 11:25:08 - log ${PRM_COUNTER}.0 -
2023/04/24 11:25:08 - log ${PRM_COUNTER}.0 - ====================
2023/04/24 11:25:08 - log ${PRM_COUNTER}.0 - Finished processing (I=0, O=0, R=1, W=1, U=0, E=0)
2023/04/24 11:25:08 - loops-copy-rows-to-result-log-counter - Pipeline duration : 0.035 seconds [ 0.035" ]
2023/04/24 11:25:08 - loops-process-rows-from-memory - Finished action [loops-copy-rows-to-result-log-counter.hpl] (result=[true])
2023/04/24 11:25:08 - loops-process-rows-from-memory - Finished action [loops-copy-rows-to-result.hpl] (result=[true])
2023/04/24 11:25:08 - loops-process-rows-from-memory - Workflow execution finished
2023/04/24 11:25:08 - Hop - Workflow execution has ended
2023/04/24 11:25:08 - loops-process-rows-from-memory - Workflow duration : 0.65 seconds [ 0.650" ]
2023/04/24 11:25:08 - loops-copy-rows-to-result-log-counter - Execution finished on a local pipeline engine with run configuration 'local' As you may have noticed, this way of looping is not very transparent. There is no way to pick up the stream values you want to pass to the second pipeline. You’ll need to log information to the logs if you want to have a clear view on what is happening in your loop. All of this combined makes it hard to maintain and debug this type of loops.
Pipeline and Workflow executor
The Workflow executor^ and Pipeline executor^ offer flexible and elegant ways to run workflows and pipelines from within an existing pipeline.
Pipeline Executor
The pipeline executor is a relatively simple but very powerful transform.
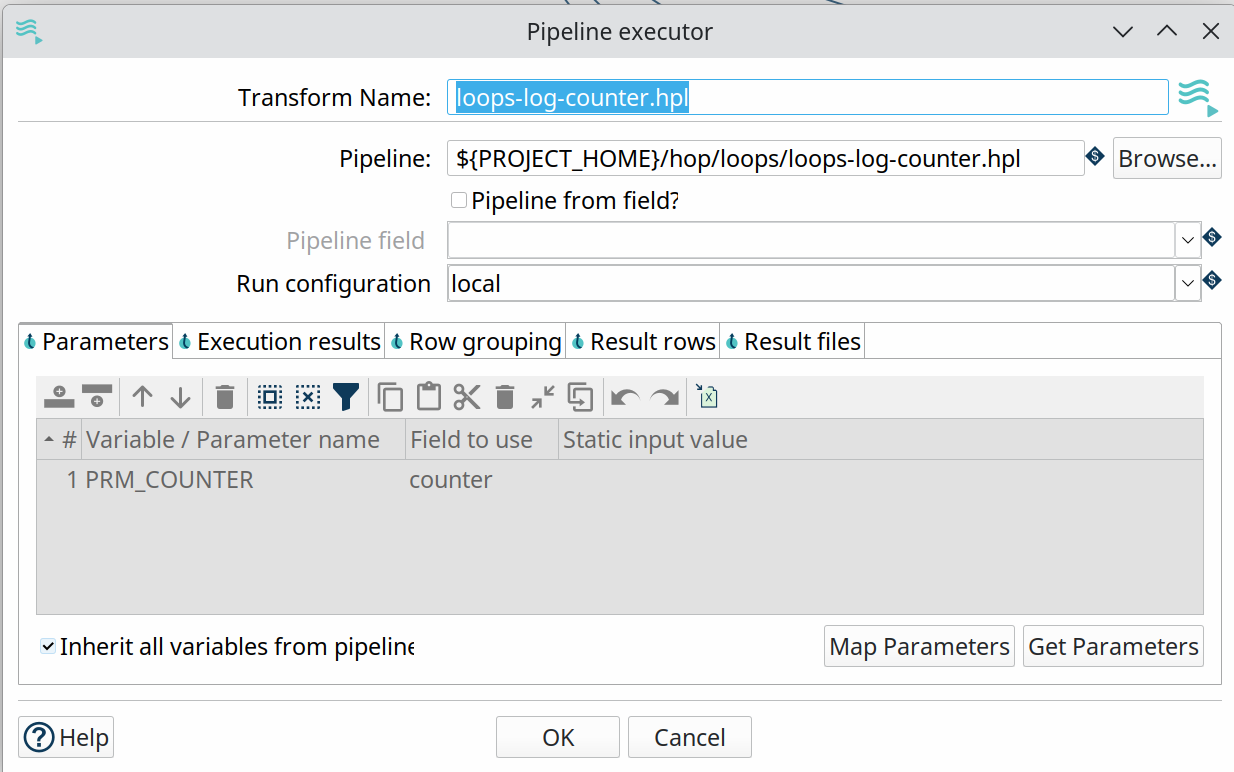
Specify a name for the pipeline you want to execute (or accept the pipeline name from a field), specify a run configuration, map the child pipeline’s parameters to fields in your current pipeline, and done.
The pipeline executor transform will send rows to the child pipeline one by one by default. This default behavior can be changed in the Row grouping tab. Use a Get rows from result^ transform in the child pipeline to fetch the rows if you’re sending more than one row to the child pipeline.
Looping over a list of values to send to your child pipeline is not necessarily the last action you want to perform in your main pipeline.
There are 5 possibilities to create hops from the pipeline executor transform to later transforms in the pipeline.
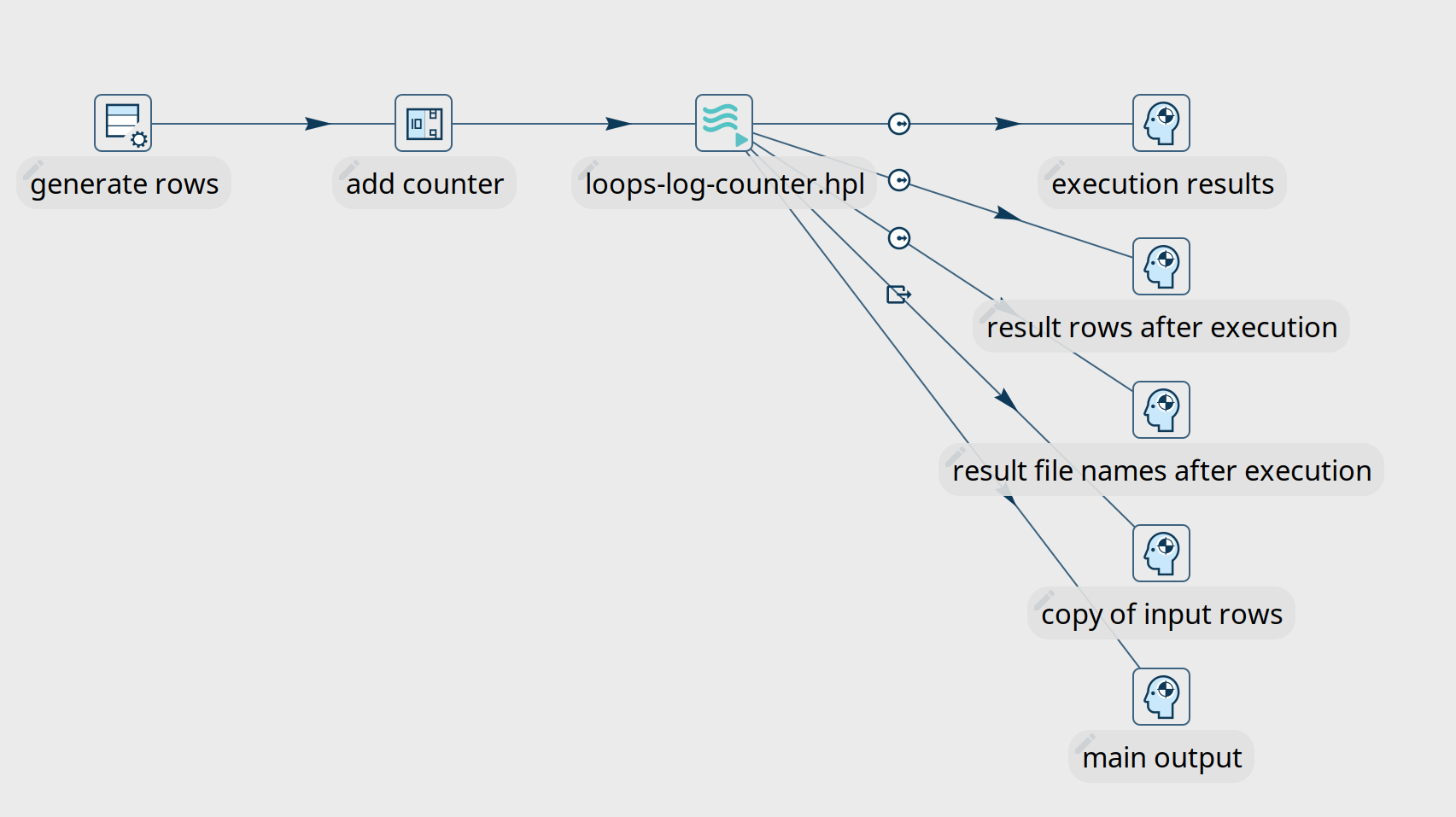
Pipeline Executor - execution results
This hop type returns execution results and metrics from the various child pipeline runs.
It’s a good idea to at least check if there have been any issues in one of your child pipelines with the ExecutionResult, ExecutionExitStatus or ExecutionNrErrors fields.
| Fieldname | Type | Description |
|---|---|---|
ExecutionTime | Integer | the time it took to execute the child pipeline |
ExecutionResult | Boolean | the result of the child pipeline execution (Y/N) |
ExecutionNrErrors | Integer | the number of errors encountered in the child pipeline execution |
ExecutionLinesRead | Integer | number of lines read from previous transforms (in the child pipeline) |
ExecutionLinesWritten | Integer | number of lines written to following transforms (in the child pipeline) |
ExecutionLinesInput | Integer | number of lines read from physical I/O like files or databases |
ExecutionLinesOutput | Integer | number of lines written to physical I/O like files or databases |
ExecutionLinesRejected | Integer | number of rejected lines in the child pipeline |
ExecutionLinesUpdated | Integer | number of updated lines in the child pipeline |
ExecutionLinesDeleted | Integer | number of deleted lines in the child pipeline |
ExecutionFilesRetrieved | Integer | number of retrieved files in the child pipeline |
ExecutionExitStatus | Integer | exit status of the child pipeline |
ExecutionLogText | String | the full logging text for the child pipeline’s execution |
ExecutionLogChannelId | String | log channel id for the child pipeline’s execution |
Pipeline Executor - Result rows after execution
This rowset receives data that was copied to memory by the child pipeline, e.g. with a Copy rows to result transform. Use the "Result rows" tab in the pipeline executor transform to specify which fields you expect to receive from the child pipelines.
Pipeline Executor - Result file names after execution
This rowset will contain any filename that was copied to the results, e.g. with the Add filenames to result in the Content tab of the Text file input^ transform.
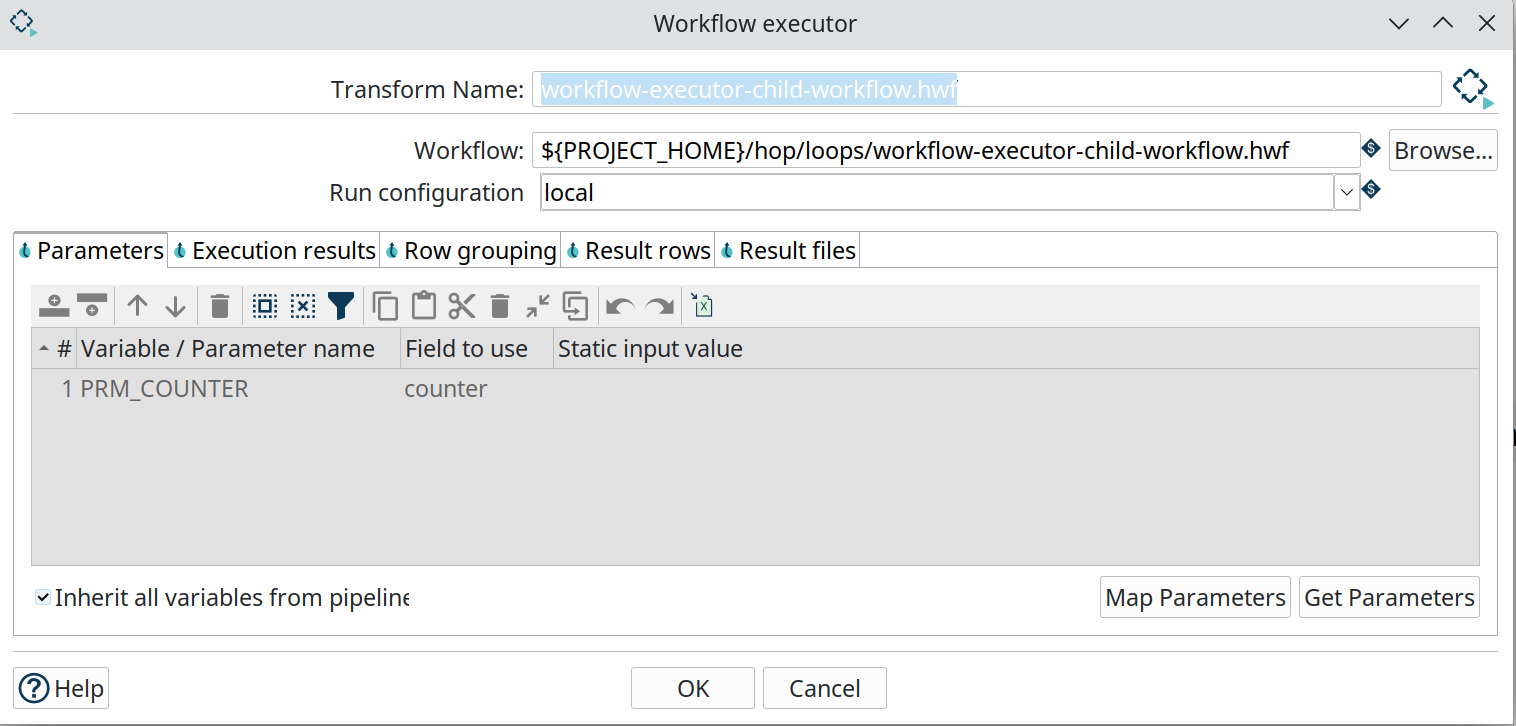
Workflow Executor
The workflow executor transform is similar to the pipeline executor transform but, as the name implies, lets you run workflows from within a pipeline.
Specify a name for the workflow you want to execute, specify a run configuration, map the child workflow’s parameters to fields in your pipeline, and done.
The workflow executor transform will send rows to the workflow one by one by default. This default behavior can be changed in the Row grouping tab.
Again, similar to the pipeline executor transform, Looping over a list of values to send to your child workflow is not necessarily the last action you want to perform in your main pipeline.
There are 4 possibilities to create hops from the workflow executor transform to later transforms in the pipeline.
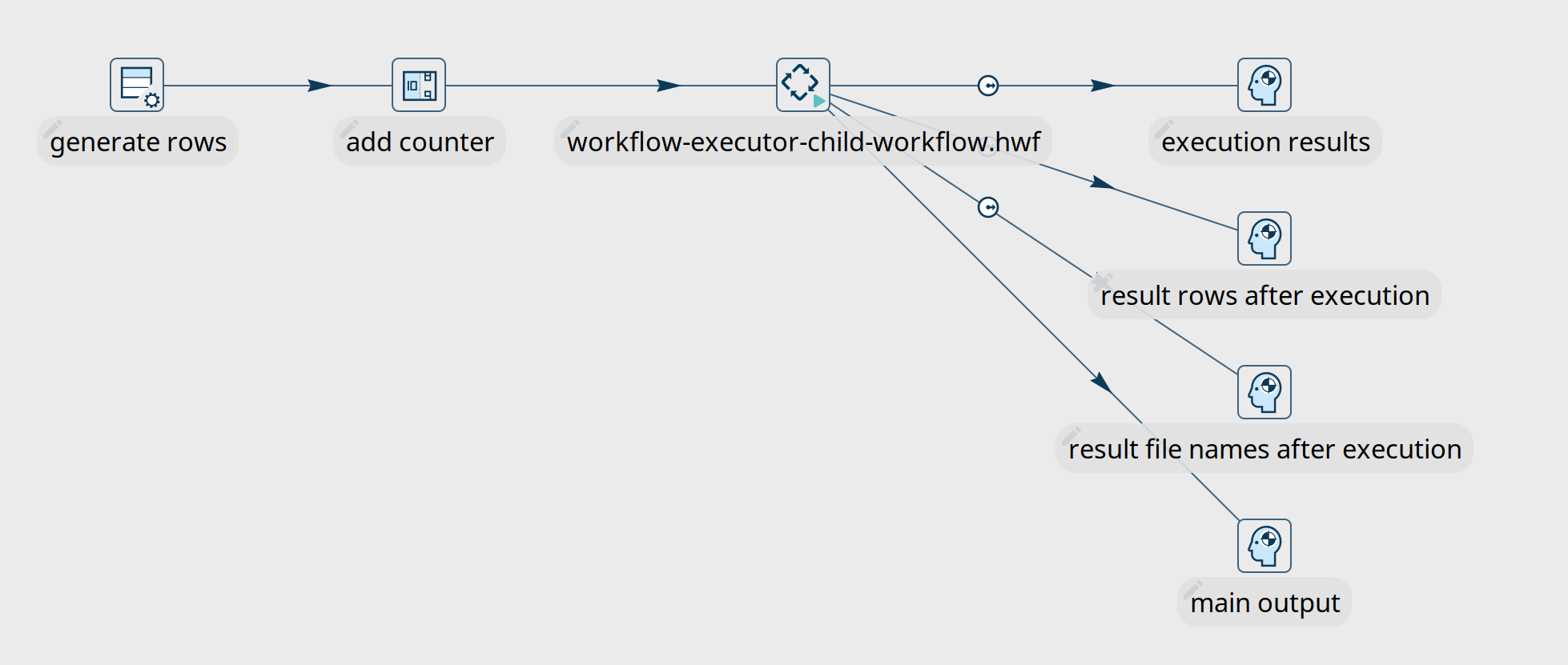
Workflow Executor - Execution Results
This hop type returns execution results and metrics from the various child workflow runs.
It’s a good idea to at least check if there have been any issues in one of your child workflow runs with the ExecutionResult, ExecutionExitStatus or ExecutionNrErrors fields.
| Fieldname | Type | Description |
|---|---|---|
ExecutionTime | Integer | the time it took to execute the child workflow |
ExecutionResult | Boolean | the result of the child workflow execution (Y/N) |
ExecutionNrErrors | Integer | the number of errors encountered in the child workflow execution |
ExecutionLinesRead | Integer | number of lines read from previous transforms (in the child workflow) |
ExecutionLinesWritten | Integer | number of lines written to following transforms (in the child workflow) |
ExecutionLinesInput | Integer | number of lines read from physical I/O like files or databases |
ExecutionLinesOutput | Integer | number of lines written to physical I/O like files or databases |
ExecutionLinesRejected | Integer | number of rejected lines in the child workflow |
ExecutionLinesUpdated | Integer | number of updated lines in the child workflow |
ExecutionLinesDeleted | Integer | number of deleted lines in the child workflow |
ExecutionFilesRetrieved | Integer | number of retrieved files in the child workflow |
ExecutionExitStatus | Integer | exit status of the child workflow |
ExecutionLogText | String | the full logging text for the child workflow’s execution |
ExecutionLogChannelId | String | log channel id for the child workflow’s execution |
Workflow Executor - Result rows after execution
This rowset receives data that was copied to memory by the child workflow. Use the Result rows tab in the workflow executor transform to specify which fields you expect to receive from the child workflows.
Repeat and End Repeat actions
In addition to the workflow and pipeline executor transforms, the Repeat^ and End Repeat^ actions let you build loops from a workflow.
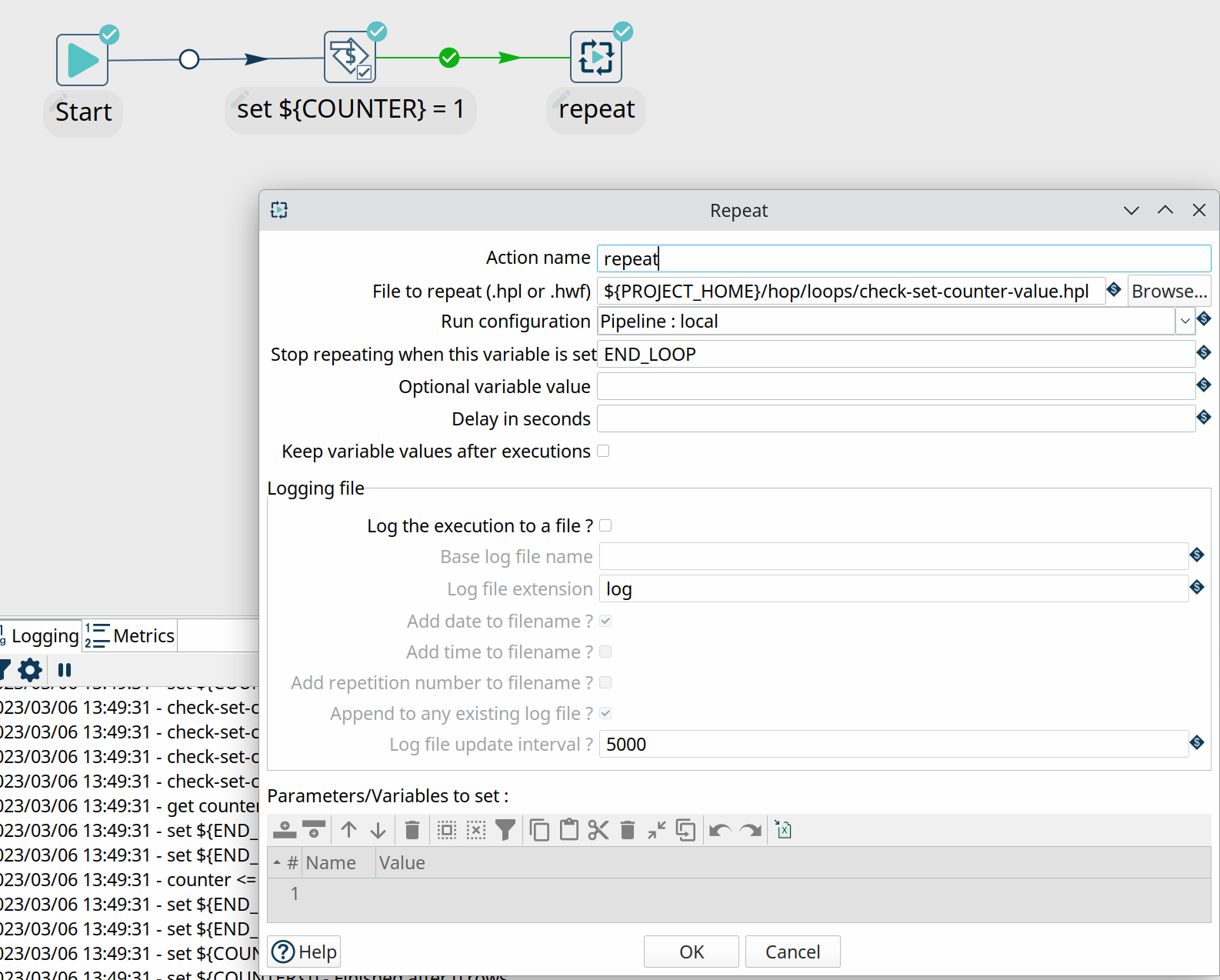
The repeat action in itself is pretty simple: it requires a workflow or pipeline and the run configuration to use.
The action will continue to execute the specified workflow or pipeline until a condition is met: either a variable is set with an (optional) value, or an End repeat action is triggered in a child workflow.
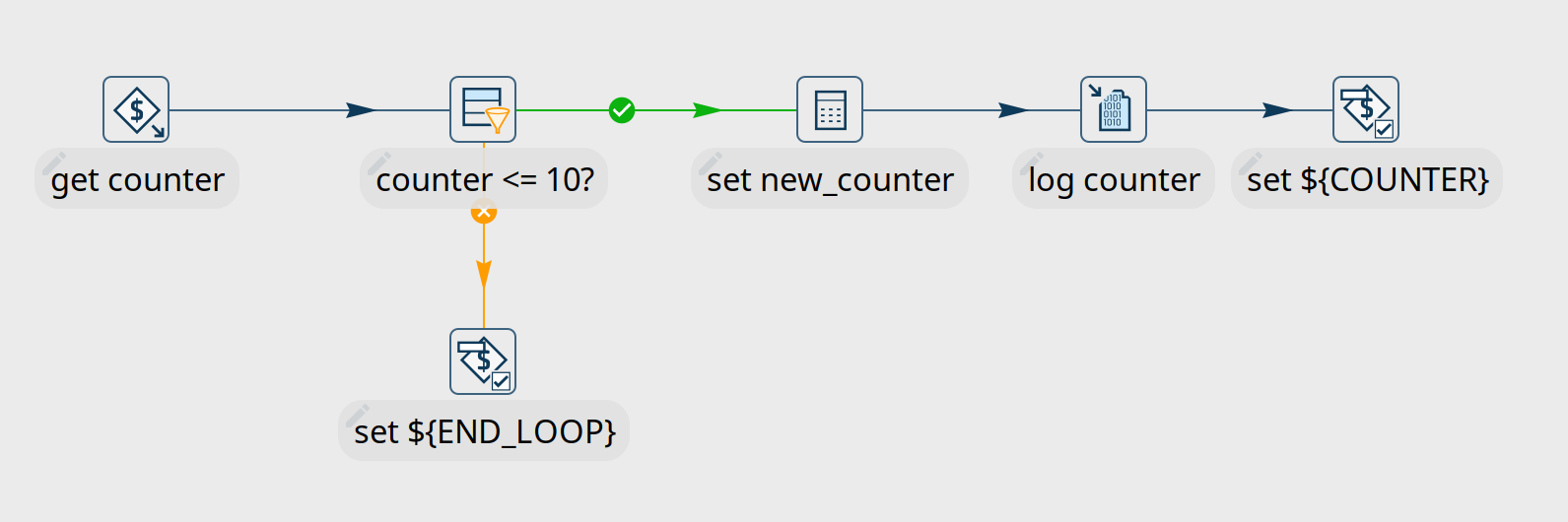
The example below runs a pipeline that increments a $${COUNTER$} variable with each run. If the variable values exceeds 10, a variable $${END_LOOP$} is set. This variable is detected by the Repeat action, and the loop stops.
Wrapping up
The options discussed here give you all the tools you need to build and run loops in your Apache Hop projects.
All of the samples discussed here are available in the samples project that is available in your Apache Hop installation (as of Apache Hop 2.5.0).
If you upgraded your projects from Pentaho Data Integration (Kettle) or intend to upgrade, now’s the time to refactor your deprecated Copy rows to result loops to any of the options discussed here.