Getting started with Apache Beam
What is Apache Beam?
Apache Beam is an advanced unified programming model that allows you to implement batch and streaming data processing jobs that run on any execution engine. Popular execution engines are for example Apache Spark, Apache Flink or Google Cloud Platform Dataflow.
How is Hop using Beam?
Hop is using the Beam API to create Beam pipelines based off of your visually designed Hop pipelines. The terminology of Hop and Beam are aligned because they mean the same thing. Hop provides 4 standard ways to execute a pipeline that you designed on Spark, Flink, Dataflow or on the Direct runner.
Here is the documentation for the relevant plugins:
How are my pipelines executed?
An Apache Hop pipeline is just metadata. The various beam pipeline engine plugins look at this metadata one transform at a time. It decides what to do with it based on a Hop transform handler which is provided. The transforms are in general split into a different types described below.
Beam specific transforms
There are a number of Beam specific transforms available which only work on the provided Beam pipeline execution engines. For example: Beam Input which reads text file data from one or more files or Beam BigQuery Output which writes data to BigQuery.
You can find these transforms in the Big Data category and their names all start with Beam to make is easy to recognize them.
Here is an example of a simple pipeline which read files in a folder (on gs://), filters out data from California, removes and renames a few fields and writes the data back to another set of files:

Universal transforms
There are a few transforms which are translated into Beam variations:
-
Memory Group By: This transform allows you to aggregate data across large data volumes. When using the Beam engines it uses
org.apache.beam.sdk.transforms.GroupByKey. -
Merge Join: You can join 2 data sources with this transform. The main difference is that in the Beam engines the input data doesn’t need to be sorted. The Beam class used to perform this is:
org.apache.beam.sdk.extensions.joinlibrary.Join. -
Generate Rows: This transform is used to generate (empty/static) rows of data. It can be either a fixed number, or it can generate rows indefinitely. When using the Beam engines it uses
org.apache.beam.sdk.io.synthetic.SyntheticBoundedSourceororg.apache.beam.sdk.io.synthetic.SyntheticUnboundedSource.
Unsupported transforms
A few transforms are simply not supported because we haven’t found a good way to do this on Beam yet:
-
Group By : Use the
Memory Group Byinstead
All other transforms
All other transforms are simply supported. They are wrapped in a bit of code to make the exact same code that runs on the Hop local pipeline engine work in a Beam pipeline. There are a few things to mention though.
| Special case | Solution |
|---|---|
Info transforms | Some transforms like |
Target transforms | Sometimes you want to target specific transforms like in |
Non-Beam input transforms | When you’re reading data using a non-beam transform (see
|
Non-Beam Output transforms | The insistence of a Beam pipeline to run work in parallel can also trip you up on the output side. In rare cases maybe you don’t want a server to be bombarded by dozens of inbound connections. To limit the amount of output copies you can include |
Row batching with non-Beam transforms | A lot of target databases like to receive rows in batches of records. So if you have a transform like for example Streaming Hop transform flush interval: how long in time are rows kept and batched up? If you care about latency make this lower (500 or lower). If you have a long-running batching pipeline, make it higher (10000 or higher perhaps). Hop streaming transforms buffer size: how many rows are being batched? Consider making it the same as the batching size you use in your transform metadata (e.g. Please note that these are maximum values. If the end of a bundle is reached in a pipeline rows are always forced to the transform code and as such pushed to the target system. To get an idea of how many times a batching buffer is flushed to the underlying transform code (and as such to for example a remote database) we added a
|

Fat jars?
A fat jar is often used to package up all the code you need for a particular project. The Spark, Flink and Dataflow execution engines like it since it massively simplifies the Java classpath when executing pipelines. Apache Hop allows you to create a fat jar in the Hop GUI with the Tools/Generate a Hop fat jar… menu or using the following command:
sh hop-config.sh -fj /path/to/fat.jarThe path to this fat jar can then be referenced in the various Beam runtime configurations. Note that the current version of Hop and all its plugins are used to build the fat jar. If you install or remove plugins or update Hop itself make sure to remember to generate a new fat jar or to update it.
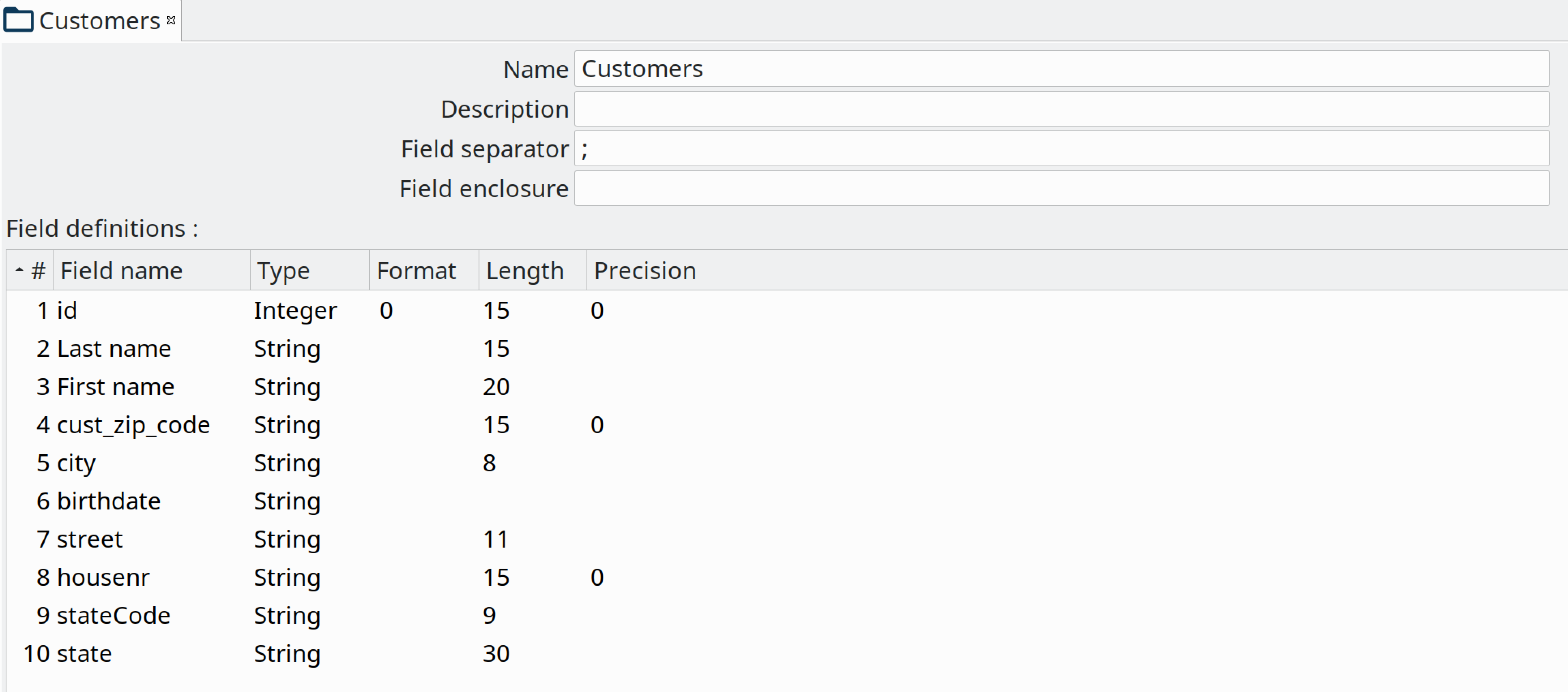
Beam File definitions
The Beam Input and Beam Output transforms expect you to define the layout of the file(s) being read or written.
Current limitations
There are some specific advantages to using engines like Spark, Flink and Dataflow. However, with it come some limitations as well…
-
Previewing data is not available (yet). Because of the distributed nature of execution we don’t have a great way to acquire preview data.
-
Unit testing: not available for similar reasons compared to previewing or debugging. To test your Beam pipelines pick up data after a pipeline is done and compare that to a golden data set in another pipeline running with a "Local Hop" pipeline engine.
-
Debugging or pausing a pipeline is not supported