Avoiding Deadlocks
In Apache Hop certain pipeline designs can run into deadlocks (also known as blocking, stalling, or hanging). A common cause of deadlock arises when using the Stream Lookup transform in pipelines with large datasets. This guide explains how to identify, understand, and resolve deadlock issues involving Stream Lookup.
Understanding Pipeline Deadlocks
Deadlocks in Apache Hop occur when different transforms within a pipeline prevent each other from completing, causing the pipeline to stall indefinitely. The following factors often lead to deadlocks:
-
External locks: When a database places locks on a table, it can prevent the pipeline from progressing.
-
Pipeline design issues: Transforms that block until previous transforms complete can create deadlocks, especially when processing large datasets locally.
-
Buffer limits and rowset size: Pipelines with splits and rejoining streams depend on appropriate rowset sizes to avoid deadlocks.
How the Stream Lookup Transform Can Cause Deadlocks
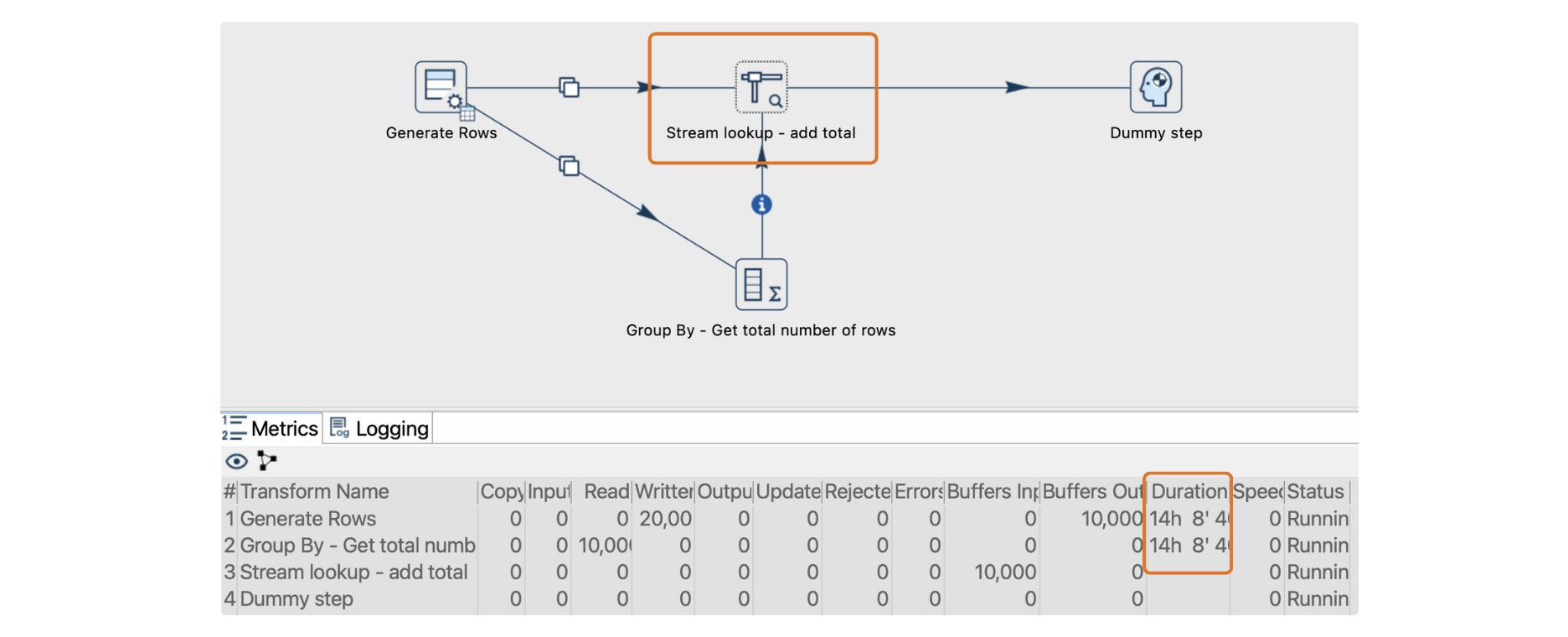
Deadlocks often occur with the Stream Lookup transform in pipelines processing a high volume of rows. Here’s a scenario illustrating how deadlocks occur:
-
Pipeline configuration: The pipeline includes a
Generate Rowstransform that splits data into two streams, one going directly to the Stream Lookup transform and the other passing through an intermediate transform, likeGroup By. -
Rowset limit: Assume the Rowset size for the local Pipeline Run Configuration is set to 10,000 rows, meaning each hop can temporarily store up to 10,000 rows between transforms.
-
Overflow: If the pipeline generates 10,001 rows, the rowset buffer will reach its 10,000-row capacity, causing the pipeline to halt until downstream transforms process some rows.
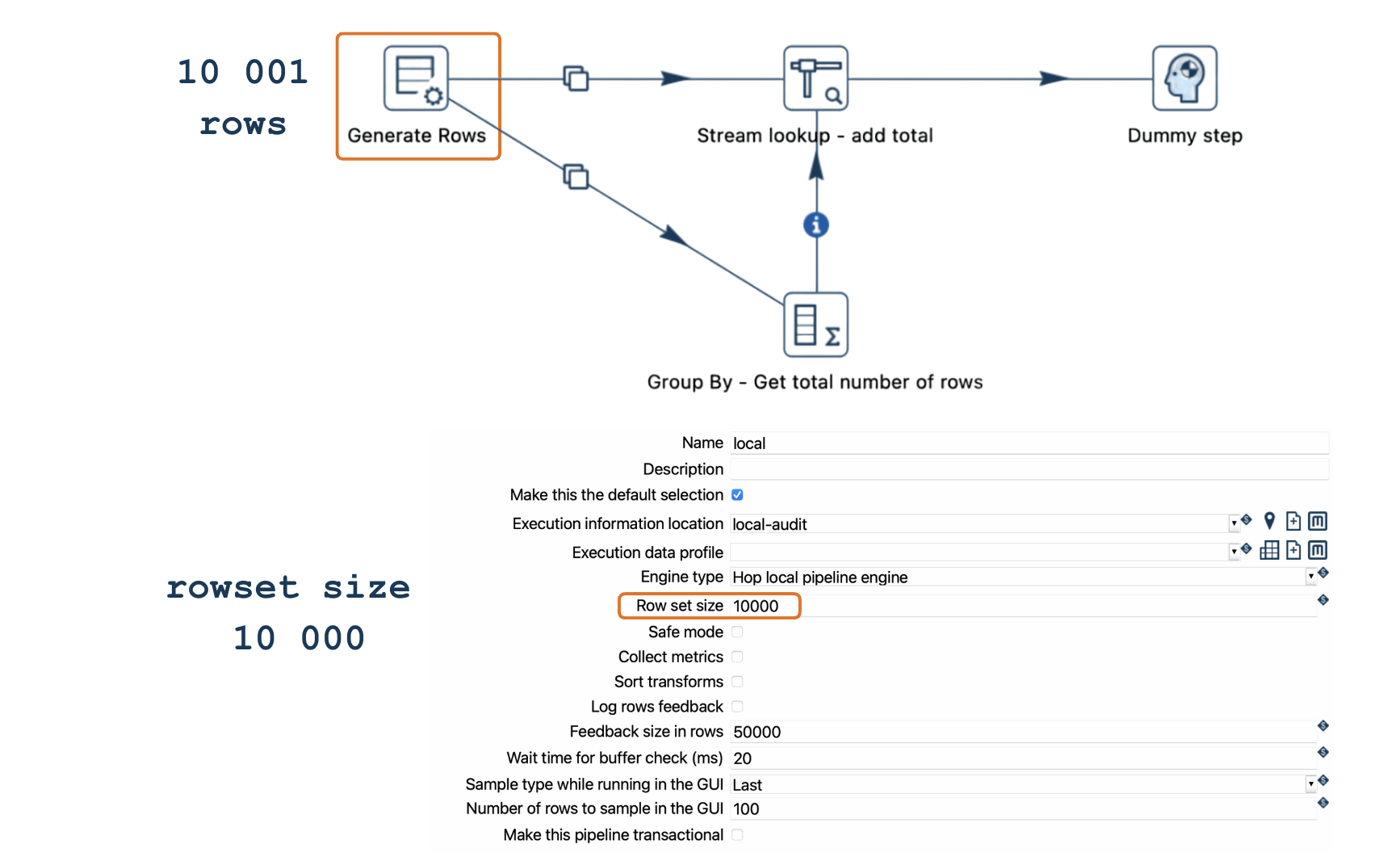
When Stream Lookup waits for data from both streams but encounters a full buffer in one stream, both streams are unable to proceed, causing the entire pipeline to deadlock.
Solutions to Avoid Deadlocks
1. Adjust Rowset size(with caution)
Increasing the rowset size can offer a short-term fix by buffering more rows, but it should be used cautiously. Larger rowsets increase memory usage and may reduce performance for large datasets.
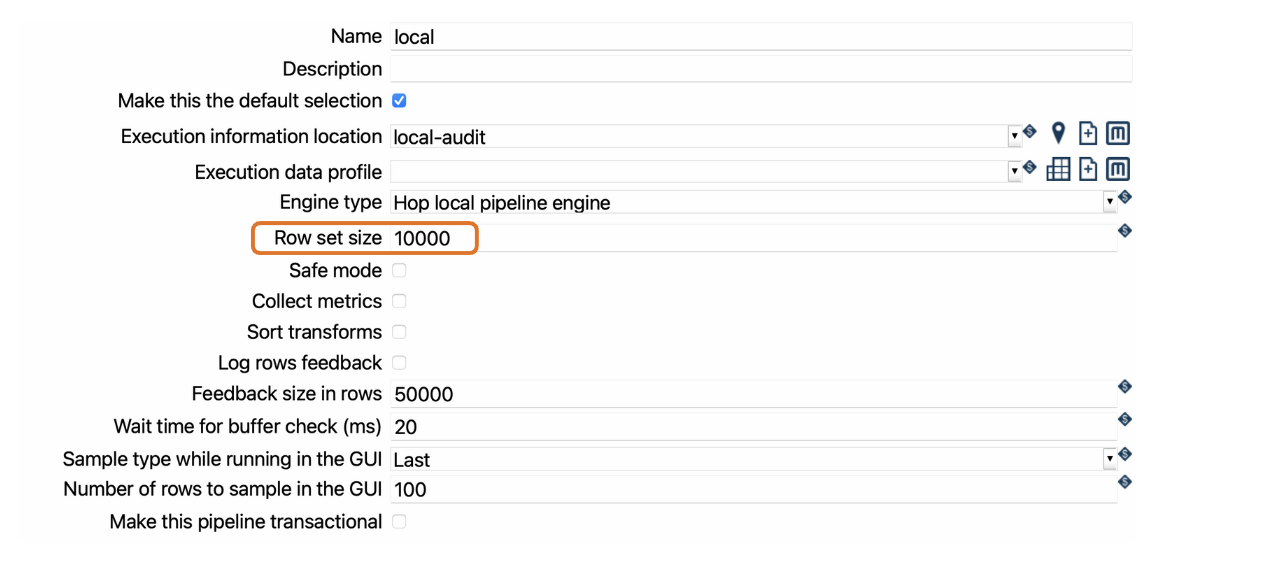
-
A pipeline uses a Pipeline Run Configuration, which specifies the engine type.
-
If using the
Localengine type, you can modify theRowset sizeoption to match your dataset and pipeline design requirements.
2. Separate input streams
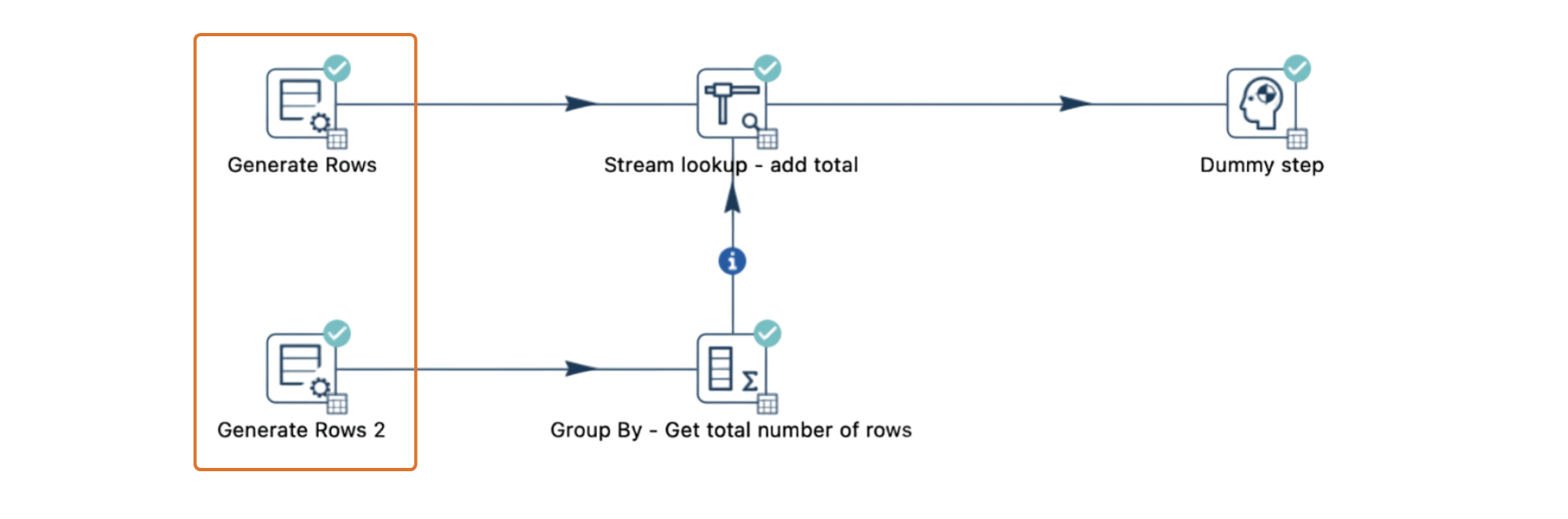
A more effective solution is to split input data streams into two independent copies, allowing each stream to operate separately. This avoids the deadlock from bottlenecked transforms in a single stream and allows Stream Lookup to function smoothly.
3. Divide pipeline into smaller units
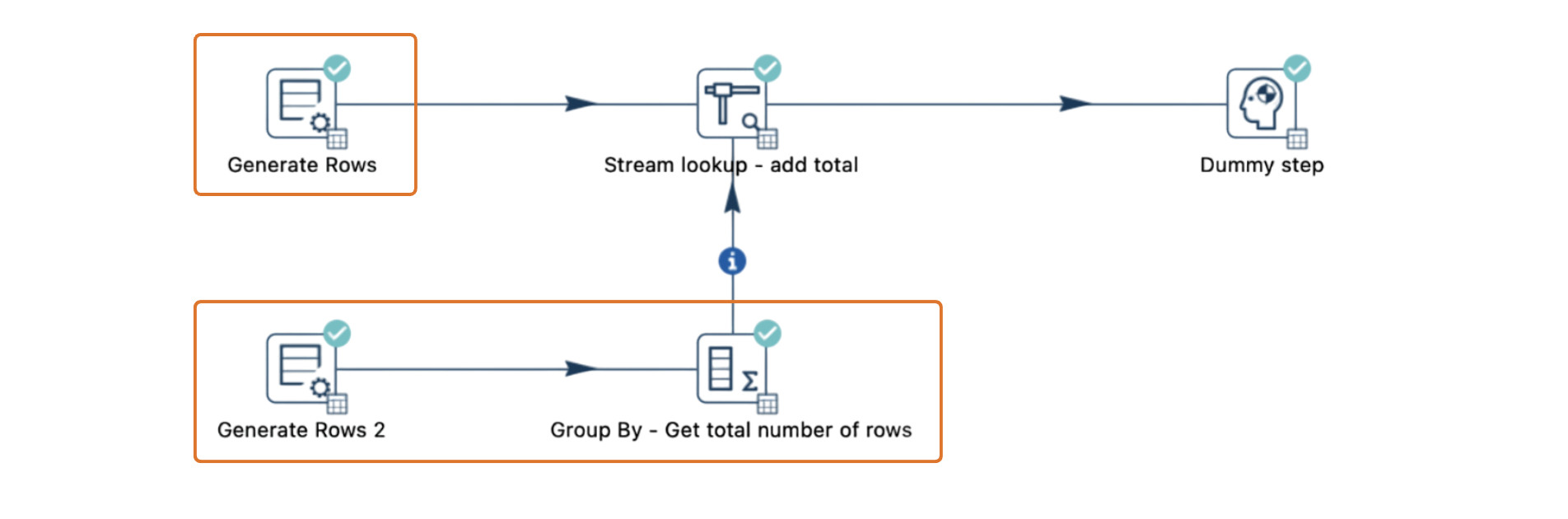
Dividing the pipeline into smaller, separate pipelines allows you to process data in stages, using intermediate tables or files for data handoff. This modular approach is highly effective in avoiding buffer-related deadlocks, especially in pipelines with multiple stream joins.
4. Use the blocking transform
For pipelines requiring sequential processing, the "Blocking" transform can manage flow control by ensuring one stream fully completes before moving to the next.
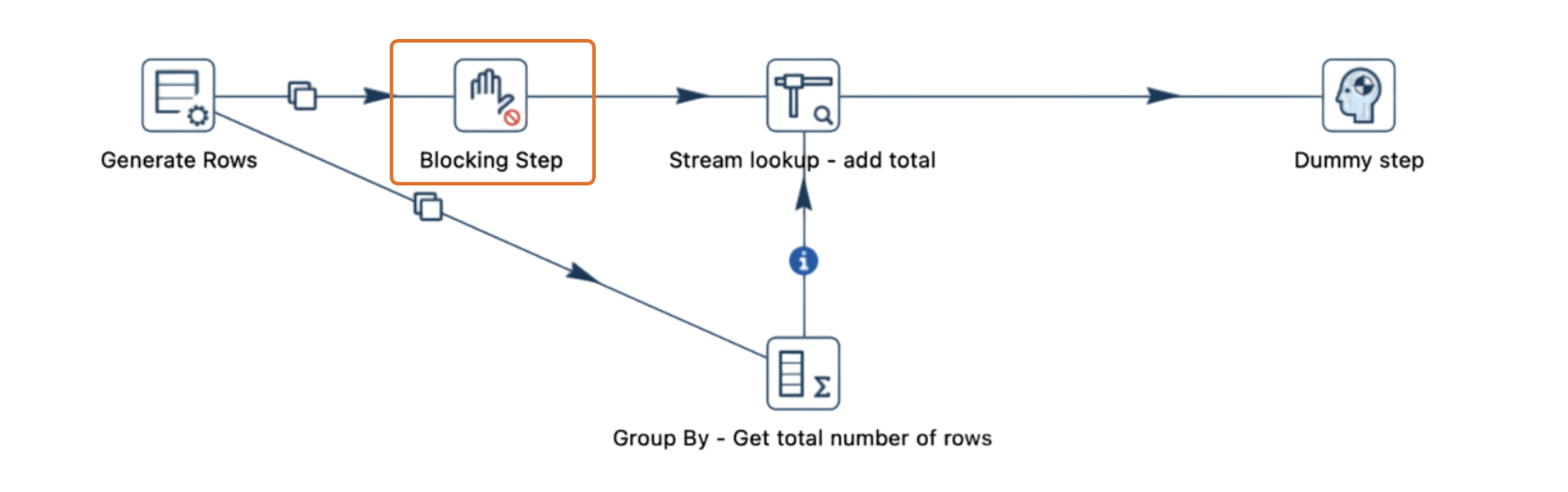
-
Configure the Blocking transform with the
Pass all rowsoption to handle streams in a sequential manner. -
Adjust settings like cache size within the Blocking transform for optimal performance.
How the Merge Join Transform Can Cause Deadlocks
Deadlocks can also occur with the Merge Join transform, particularly when processing large datasets or running pipelines locally. Here’s an example scenario that demonstrates how deadlocks might arise with the Merge Join transform:
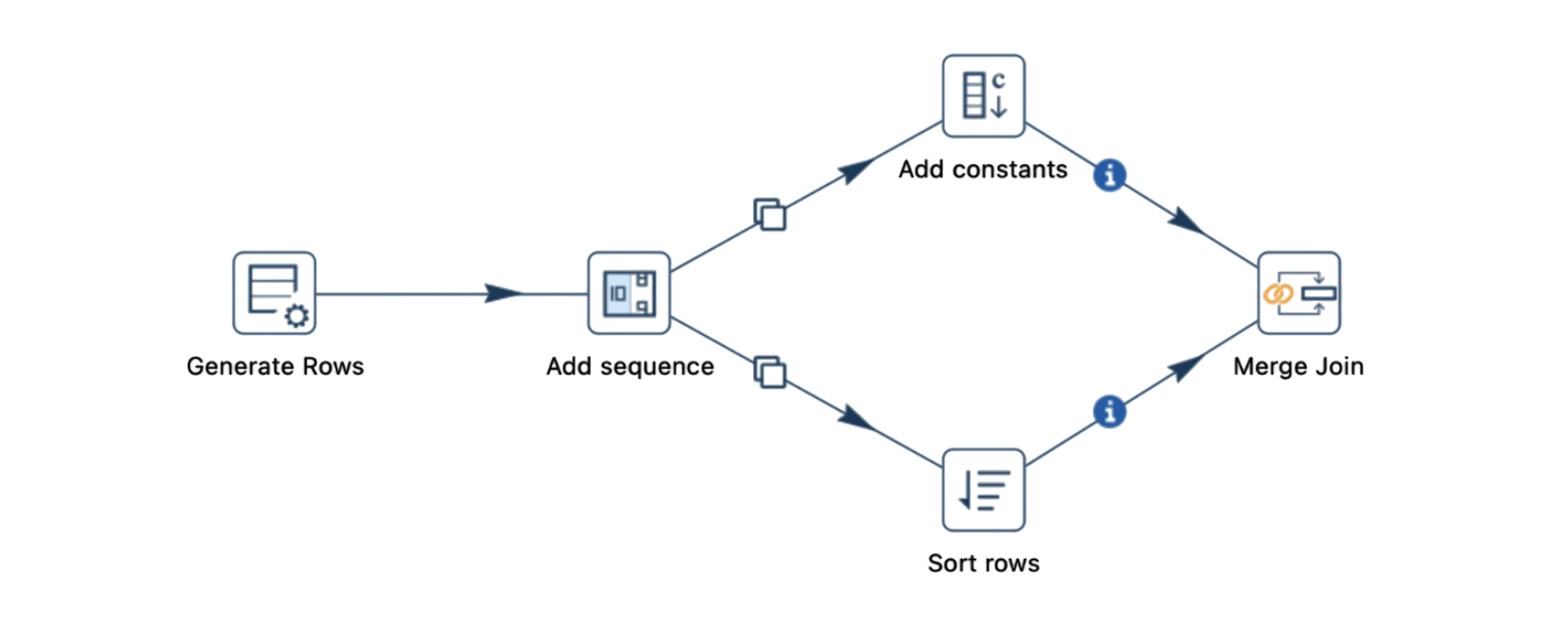
-
Pipeline Configuration: The pipeline generates rows, splits into two streams, and merges back at the Merge Join transform. One stream goes directly to Merge Join, while the other passes through an Add Constants transform and then a Sort Rows transform.
-
Rowset Limit: Suppose the Rowset size for the local Pipeline Run Configuration is set to 10,000 rows. If this pipeline generates 20,003 rows, the two streams might exceed the combined buffer capacity of 20,000 rows (10,000 for each hop), resulting in a pipeline stall.
-
Deadlock Trigger: As the rowset fills up, Merge Join may wait for rows from both sorted streams. However, if one stream’s buffer is full, neither stream can proceed, leading to a deadlock.
Solutions to Avoid Deadlocks with Merge Join
1. Adjust Rowset Size (with Caution)
As we mentioned in the previous example, increasing the rowset size can temporarily buffer more rows, which may prevent deadlocks in smaller data volumes. However, larger rowsets increase memory usage and can reduce performance, especially with larger datasets.
-
Open the pipeline’s Pipeline Run Configuration, which sets the engine type.
-
When using the
Localengine type, adjust theRowset sizeoption to fit your data size and pipeline design.
2. Sort Both Streams Before Merging
Ensure that both input streams are sorted before they reach the Merge Join transform. Sorting allows rows to flow smoothly and sequentially, reducing the likelihood of a buffer overflow and subsequent deadlock.
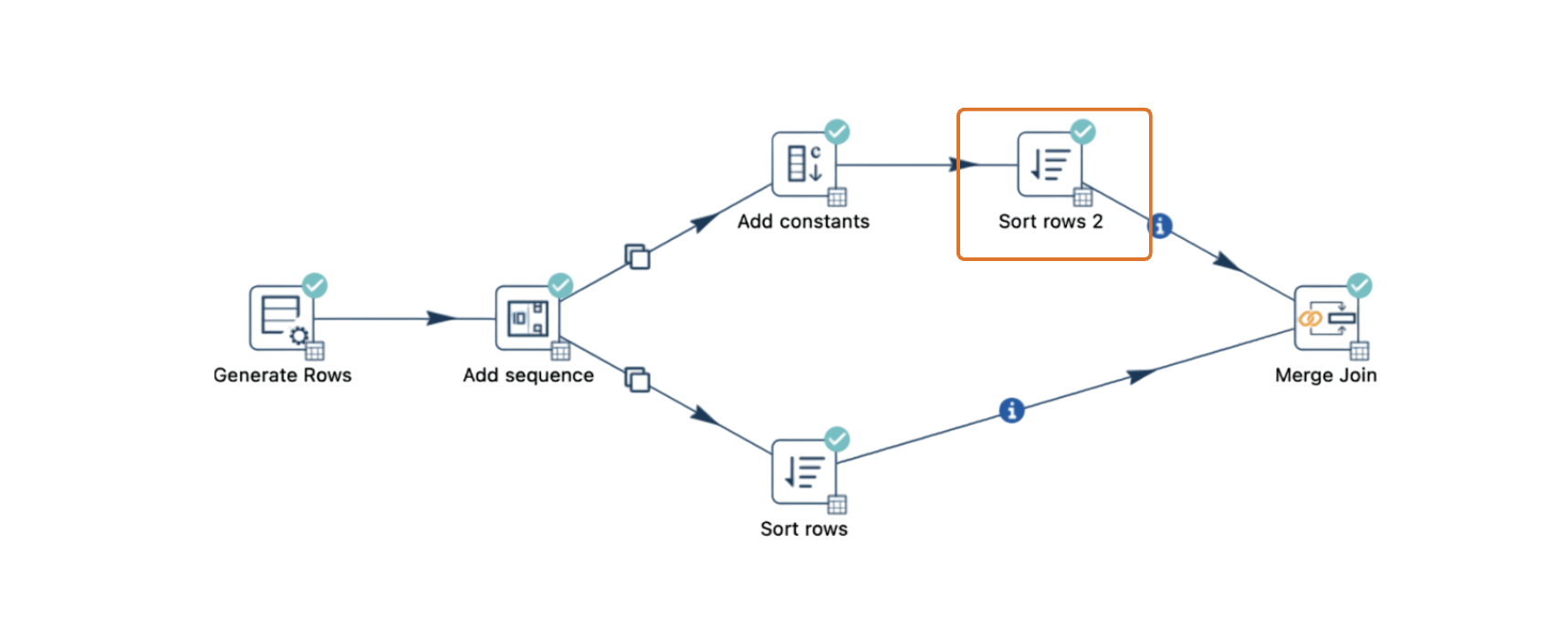
-
Use the Sort Rows transform on each stream before joining them.
-
If the data comes from a database and uses consistent data types, sorting within the database may be sufficient.
3. Use the Blocking Transform
For pipelines where sequential processing is essential, the Blocking transform can help manage flow control. Configure it to process all rows in one stream before releasing them to the next transform.
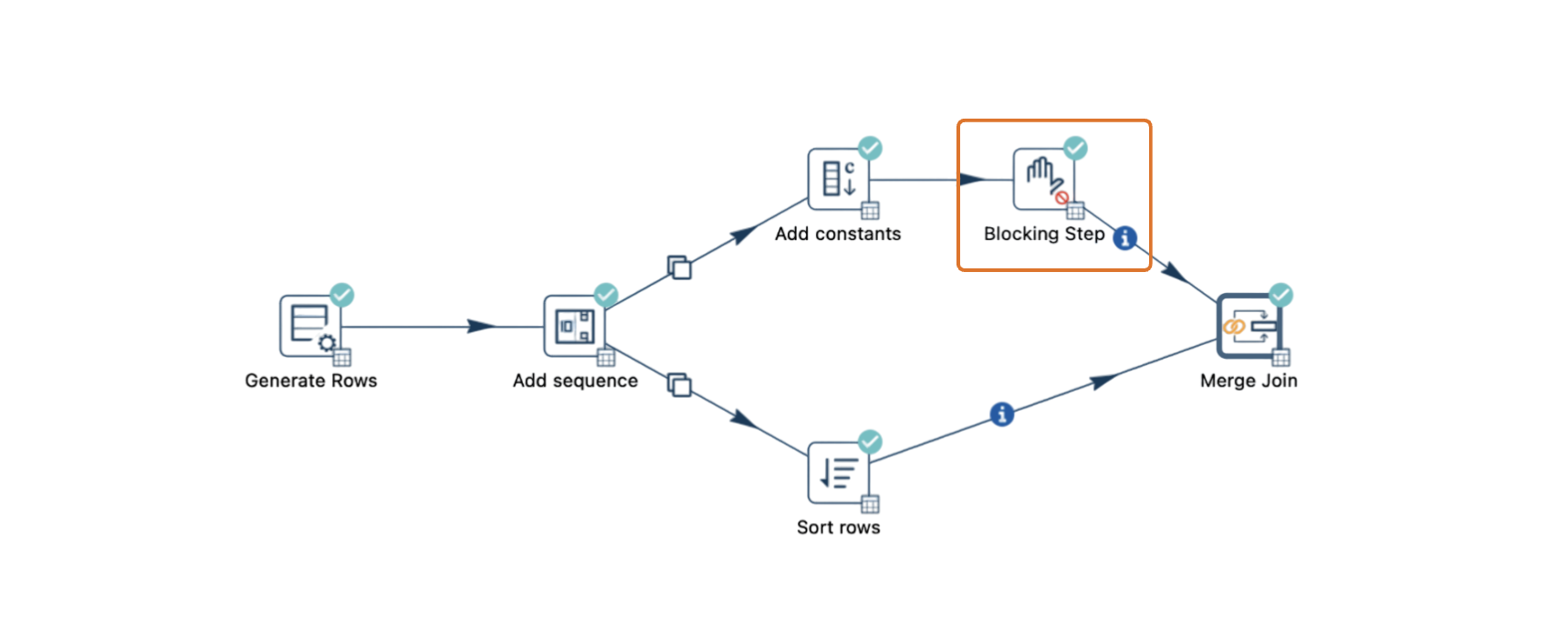
-
Set the Blocking transform’s Pass all rows option to enable sequential row processing.
-
Fine-tune the cache size in the Blocking transform settings as necessary for optimal performance.