Pipelines
Pipelines overview
Pipelines, together with workflows, are the main building blocks in Hop. Pipelines perform the heavy data lifting: in a pipeline, you read data from one or more sources, perform a number of operations (joins, lookups, filters and lots more) and finally write the processed data to one or more target platforms.
Pipelines are a network of transforms, connected by hops. Just like the actions in a workflow, each transform is a small piece of functionality. The combination of a number of transforms allow Hop developers to build powerful data processing and, in combination with workflows, orchestration solutions.
Even though there is some visual resemblance, workflows and pipelines operate very differently.
The core principles of pipelines are:
-
pipelines are networks. Each transform in a pipeline is part of the network.
-
a pipeline runs all of its transforms in parallel. All transforms are started and process data simultaneously. In a simple pipeline where you read data from a large file, do some processing and finally write to a database table, you’re typically still reading from the file while you’re already loading data to the database.
-
data flows through the various transforms in a pipeline over hops. In contrast to workflow hops, pipeline hops typically don’t have an exit status. Pipelines do have some routing capabilities through e.g. Filter Rows transform and error handling, but the core pipeline principle still applies: the pipeline is a network, and data flow through the network in parallel.
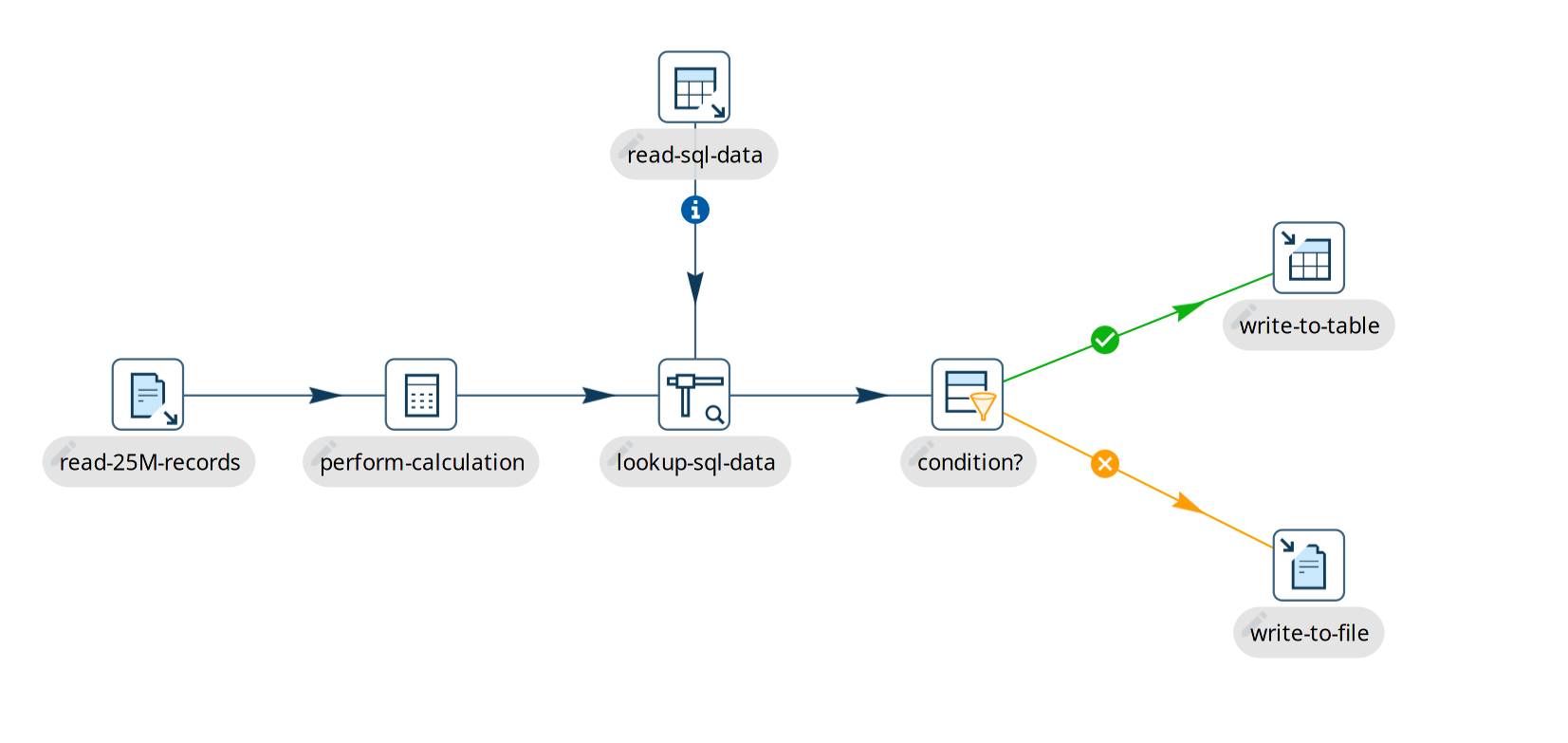
Example pipeline walk-through
The example below shows a very basic pipeline. This is what happens when we run this pipeline:
-
the pipeline has 7 transforms. All 7 of these transforms become active when we start the pipeline.
-
the "read-25M-records" transform starts reading data from a file, and pushes that data down the stream to "perform-calculations" and the following transforms. Since reading 25 million records takes a while, some data may already have finished processing while we’re still reading records from the file.
-
the "lookup-sql-data" matches data we read from the file with data we retrieved from the "read-sql-data" transform. The Stream Lookup accepts input from the "read-sql-data", which is shown with the information icon
 on the hop.
on the hop. -
once the data from the file and sql query are matched, we check a condition with the Filter Rows transform in "condition?". The output of this data is passed to "write-to-table" or "write-to-file", depending on whether the condition outcome was true or false.